おすすめの記事
すべてのカテゴリーで最もよくある質問をいくつか紹介します。wandb.initはトレーニングプロセスにどのような影響を与えますか?- Sweeps でカスタム CLI コマンドを使用するにはどうすればよいですか?
- メトリクスをオフラインで保存し、後で W&B に同期することは可能ですか?
- トレーニングコード内で Run の名前を設定するにはどうすればよいですか?
まだお探しの情報が見つかりませんか?
学生としてアカデミックプランを利用できますか?
学生としてアカデミックプランを利用できますか?
- wandb.com の料金ページ にアクセスします。
- アカデミックプランを申請します。
- または、30 日間のトライアルから開始し、W&B アカデミック申請ページ にアクセスしてアカデミックプランに切り替えることも可能です。
誰が私の Artifacts にアクセスできますか?
誰が私の Artifacts にアクセスできますか?
- プライベートプロジェクトでは、Teams メンバーのみが Artifacts にアクセスできます。
- パブリックプロジェクトでは、すべての Users が Artifacts を読み取ることができますが、作成や変更ができるのは Teams メンバーのみです。
- オープンプロジェクトでは、すべての Users が Artifacts の読み書きを行えます。
Artifacts ワークフロー
このセクションでは、Artifacts の管理と編集のためのワークフローの概要を説明します。多くのワークフローは、W&B に保存されたデータへのアクセスを提供する W&B API(クライアントライブラリ のコンポーネント)を利用します。Runs にログ記録されたデータに、プログラムから直接アクセスするにはどうすればよいですか?
Runs にログ記録されたデータに、プログラムから直接アクセスするにはどうすればよいですか?
wandb.log で記録されたメトリクスを追跡します。API を使用して History オブジェクトにアクセスします:Sweep に値を追加する方法はありますか、それとも新しく開始する必要がありますか?
Sweep に値を追加する方法はありますか、それとも新しく開始する必要がありますか?
シート数を増やす方法はありますか?
シート数を増やす方法はありますか?
- 担当の Account Executive またはサポートチーム (support@wandb.com) に連絡して支援を依頼してください。
- 組織名(Organization name)と希望するシート数をお知らせください。
Plotly や Bokeh のチャートを Tables に追加するにはどうすればよいですか?
Plotly や Bokeh のチャートを Tables に追加するにはどうすればよいですか?
- Plotly を使用する場合
- Bokeh を使用する場合
同じサービスアカウントを複数の Teams に追加することは可能ですか?
同じサービスアカウントを複数の Teams に追加することは可能ですか?
レポートに複数の著者を設定する
レポートに複数の著者を設定する

ローカルインスタンスの管理者の場合、どのように管理すればよいですか?
ローカルインスタンスの管理者の場合、どのように管理すればよいですか?
Weights and Biases の Anaconda パッケージはありますか?
Weights and Biases の Anaconda パッケージはありますか?
pip または conda のいずれかを使用してインストール可能な Anaconda パッケージがあります。conda の場合は、conda-forge チャンネルからパッケージを取得してください。- pip
- conda
匿名 Users が利用できない機能は何ですか?
匿名 Users が利用できない機能は何ですか?
- データの永続性なし: 匿名アカウントでは Runs は 7 日間保存されます。匿名 Run のデータは、実際のアカウントに保存することで引き継ぐことができます。
-
Artifacts のログ記録不可: 匿名 Run に Artifacts を記録しようとすると、コマンドラインに警告が表示されます:
- プロフィールや設定ページなし: 実際のアカウントでのみ有用なため、UI には特定のページが含まれません。
各 Artifact バージョンはどのくらいのストレージを使用しますか?
各 Artifact バージョンはどのくらいのストレージを使用しますか?

cat.png と dog.png の 2 つの画像ファイルを含む animals という名前の画像 Artifact を例に考えます:v0 が割り当てられます。新しい画像 rat.png を追加すると、以下の内容を含む新しい Artifact バージョン v1 が作成されます:v1 は合計 6MB を追跡しますが、残りの 3MB を v0 と共有しているため、占有するスペースは 3MB のみです。v1 を削除すると、rat.png に関連付けられた 3MB のストレージが解放されます。v0 を削除すると、cat.png と dog.png のストレージコストが v1 に転送され、そのストレージサイズは 6MB に増加します。複数のアーキテクチャーと Runs で Artifacts を使用する場合のベストプラクティスは?
複数のアーキテクチャーと Runs で Artifacts を使用する場合のベストプラクティスは?
- 異なるモデルアーキテクチャーごとに新しい Artifact を作成します。Artifacts の
metadata属性を使用して、Run のconfigと同様に、アーキテクチャーの詳細な説明を提供します。 - 各モデルについて、
log_artifactを使用して定期的にチェックポイントを記録します。W&B はこれらのチェックポイントの履歴を構築し、最新のものにlatestエイリアスを付けます。architecture-name:latestを使用して、任意のモデルアーキテクチャーの最新のチェックポイントを参照できます。
Sweep の Runs からモデルをログに記録する最善の方法は何ですか?
Sweep の Runs からモデルをログに記録する最善の方法は何ですか?
ハイパーパラメーター探索を整理するためのベストプラクティス
ハイパーパラメーター探索を整理するためのベストプラクティス
wandb.init(tags='your_tag') でユニークなタグを設定します。これにより、プロジェクトページの Runs Table で対応するタグを選択することで、プロジェクトの Runs を効率的にフィルタリングできます。wandb.init() の詳細については、wandb.init() リファレンス を参照してください。バグバウンティプログラムはありますか?
バグバウンティプログラムはありますか?
サブスクリプションをキャンセルするにはどうすればよいですか?
サブスクリプションをキャンセルするにはどうすればよいですか?
- サポートチーム (support@wandb.com) に連絡してください。
- 組織名、アカウントに関連付けられたメールアドレス、およびユーザー名を提供してください。
アカウントを企業用からアカデミック用に変更するにはどうすればよいですか?
アカウントを企業用からアカデミック用に変更するにはどうすればよいですか?
-
アカデミックメールをリンクする:
- アカウント設定にアクセスします。
- アカデミックメールを追加し、プライマリメールとして設定します。
-
アカデミックプランを申請する:
- W&B アカデミック申請ページ にアクセスします。
- 審査のために申請書を提出します。
請求先住所を変更するにはどうすればよいですか?
請求先住所を変更するにはどうすればよいですか?
Sweep がローカルにログを記録するディレクトリーを変更するにはどうすればよいですか?
Sweep がローカルにログを記録するディレクトリーを変更するにはどうすればよいですか?
WANDB_DIR を設定することで、W&B の Run データのログディレクトリーを設定できます。例:完了した Run に割り当てられたグループを後から変更することは可能ですか?
完了した Run に割り当てられたグループを後から変更することは可能ですか?
ユーザー名を変更することは可能ですか?
ユーザー名を変更することは可能ですか?
W&B クライアントは Python 2 をサポートしていますか?
W&B クライアントは Python 2 をサポートしていますか?
pip install --upgrade wandb を実行すると、0.10.x シリーズの新リリースのみがインストールされます。0.10.x シリーズのサポートには、重大なバグ修正とパッチのみが含まれます。Python 2.7 をサポートする 0.10.x シリーズの最終バージョンは 0.10.33 です。W&B クライアントは Python 3.5 をサポートしていますか?
W&B クライアントは Python 3.5 をサポートしていますか?
エポックやステップをまたいで画像やメディアを比較するにはどうすればよいですか?
エポックやステップをまたいで画像やメディアを比較するにはどうすればよいですか?
トレーニングコード内で Run の名前を設定するにはどうすればよいですか?
トレーニングコード内で Run の名前を設定するにはどうすればよいですか?
wandb.init を呼び出します。例:wandb.init(name="my_awesome_run")。レポートを WYSIWYG に変換しましたが、Markdown に戻したいです。
レポートを WYSIWYG に変換しましたが、Markdown に戻したいです。
cmd+z で元に戻せます。セッションが終了しているなどの理由で元に戻すオプションが利用できない場合は、ドラフトを破棄するか、最後に保存されたバージョンから編集することを検討してください。どちらも機能しない場合は、W&B サポートまでご連絡ください。wandb がクラッシュした場合、トレーニング Run もクラッシュしますか?
wandb がクラッシュした場合、トレーニング Run もクラッシュしますか?
削除されたアカウントで以前使用していたメールアドレスで、新しいアカウントを作成することは可能ですか?
削除されたアカウントで以前使用していたメールアドレスで、新しいアカウントを作成することは可能ですか?
誰が Teams を作成できますか?誰がチームへのメンバーの追加や削除を行えますか?誰が Projects を削除できますか?
誰が Teams を作成できますか?誰がチームへのメンバーの追加や削除を行えますか?誰が Projects を削除できますか?
Sweeps でカスタム CLI コマンドを使用するにはどうすればよいですか?
Sweeps でカスタム CLI コマンドを使用するにはどうすればよいですか?
train.py という名前の Python スクリプトをトレーニングし、スクリプトがパースする値を指定している bash ターミナルを示しています。command キーを変更します。前の例に基づくと、設定は以下のようになります:${args} キーは、スイープ設定内のすべてのパラメータに展開され、argparse 用に --param1 value1 --param2 value2 の形式でフォーマットされます。argparse 以外の追加引数については、以下のように実装してください:python が Python 2 を指す場合があります。Python 3 が呼び出されるようにするには、コマンド設定で python3 を使用してください:ダークモードはありますか?
ダークモードはありますか?
- W&B アカウント設定 に移動します。
- Public preview features セクションまでスクロールします。
- UI Display で、ドロップダウンから Dark mode を選択します。
ネットワークの問題にはどう対処すればよいですか?
ネットワークの問題にはどう対処すればよいですか?
wandb: Network error (ConnectionError), entering retry loop などの SSL またはネットワークエラーが発生した場合は、以下の解決策を試してください:- SSL 証明書をアップグレードします。Ubuntu サーバーでは
update-ca-certificatesを実行します。セキュリティリスクを軽減しながらトレーニングログを同期するには、有効な SSL 証明書が不可欠です。 - ネットワーク接続が不安定な場合は、オプションの環境変数
WANDB_MODEをofflineに設定してオフラインモードで動作させ、後でインターネット接続のあるデバイスからファイルを同期します。 - クラウドサーバーへの同期を避け、ローカルで実行される W&B Private Hosting の使用を検討してください。
SSL CERTIFICATE_VERIFY_FAILED エラーの場合、会社側のファイアウォールが原因である可能性があります。ローカル CA を設定し、以下を実行してください:export REQUESTS_CA_BUNDLE=/etc/ssl/certs/ca-certificates.crtカスタムチャートのプリセットを削除するにはどうすればよいですか?
カスタムチャートのプリセットを削除するにはどうすればよいですか?
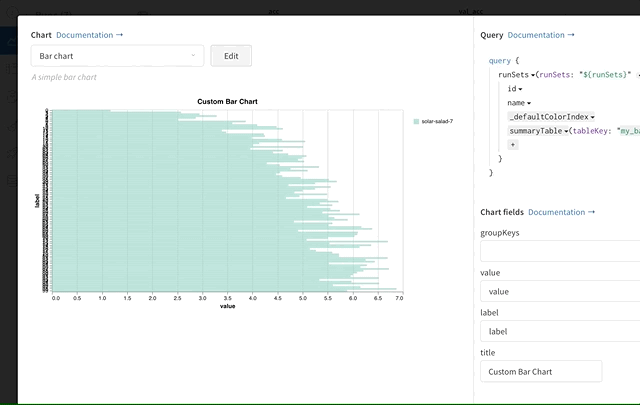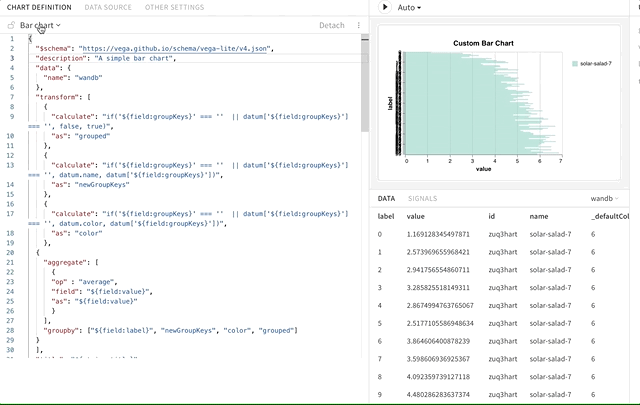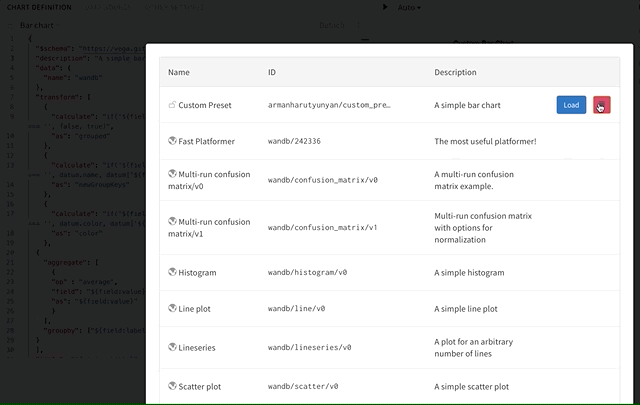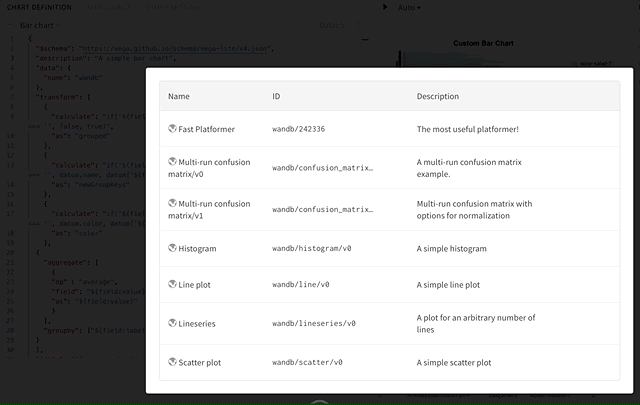
組織(Organization)アカウントを削除するにはどうすればよいですか?
組織(Organization)アカウントを削除するにはどうすればよいですか?
パネルグリッドを削除するにはどうすればよいですか?
パネルグリッドを削除するにはどうすればよいですか?
アカウントからチームを削除するにはどうすればよいですか?
アカウントからチームを削除するにはどうすればよいですか?
- 管理者としてチーム設定にアクセスします。
- ページ下部にある Delete ボタンをクリックします。
Run に名前を付けていません。この Run 名はどこから来ているのですか?
Run に名前を付けていません。この Run 名はどこから来ているのですか?
pleasant-flower-4 や misunderstood-glade-2 などがあります。`.log()` と `.summary` の違いは何ですか?
`.log()` と `.summary` の違いは何ですか?
run.log() を呼び出します。デフォルトでは、メトリクスに対して手動で設定されない限り、run.log() は Summary の値を更新します。散布図や並行座標プロットは Summary の値を使用し、折れ線グラフは run.log で記録されたすべての値を表示します。Users によっては、最後にログに記録された精度ではなく、最適(optimal)な精度を反映させるために Summary を手動で設定することを好む場合もあります。チームとエンティティ(Entity)の違いは何ですか?ユーザーにとってエンティティは何を意味しますか?
チームとエンティティ(Entity)の違いは何ですか?ユーザーにとってエンティティは何を意味しますか?
wandb.init(entity="example-team") を使用して、エンティティを個人アカウントまたはチームアカウントに設定します。チームと組織(Organization)の違いは何ですか?
チームと組織(Organization)の違いは何ですか?
wandb.init の各モードの違いは何ですか?
wandb.init の各モードの違いは何ですか?
online(デフォルト): クライアントはデータを wandb サーバーに送信します。offline: クライアントはデータを wandb サーバーに送信せず、マシン上にローカルに保存します。後でデータを同期するにはwandb syncコマンドを使用します。disabled: クライアントはモックオブジェクトを返すことで動作をシミュレートし、ネットワーク通信を一切行いません。すべてのログ記録はオフになりますが、すべての API メソッドスタブは呼び出し可能なままです。このモードは主にテストに使用されます。
W&B は TensorBoard とどう違うのですか?
W&B は TensorBoard とどう違うのですか?
- モデルの再現性: W&B は実験、探索、およびモデルの再現を容易にします。メトリクス、ハイパーパラメーター、コードバージョンをキャプチャし、モデルのチェックポイントを保存して再現性を確保します。
- 自動整理: W&B は、試行したすべてのモデルの概要を提供することで、プロジェクトの引き継ぎや休暇中の対応を効率化し、古い実験の再実行を防ぐことで時間を節約します。
- 迅速な統合: 5 分でプロジェクトに W&B を統合できます。無料のオープンソース Python パッケージをインストールし、数行のコードを追加するだけです。モデルの Run ごとにログに記録されたメトリクスとレコードが表示されます。
- 一元化されたダッシュボード: ローカル、ラボのクラスター、クラウドのスポットインスタンスなど、トレーニング場所に関わらず一貫したダッシュボードにアクセスできます。異なるマシン間で TensorBoard ファイルを管理する必要がなくなります。
- 堅牢なフィルタリングテーブル: 様々なモデルの結果を効率的に検索、フィルタリング、ソート、グループ化できます。TensorBoard が大規模プロジェクトで苦労しがちな、異なるタスクにおけるベストパフォーマンスモデルの特定も容易です。
- コラボレーションツール: W&B は、複雑な機械学習プロジェクトのコラボレーションを強化します。プロジェクトリンクを共有したり、結果共有のためにプライベートチームを活用したりできます。インタラクティブな可視化と Markdown の説明を含むレポートを作成し、作業ログやプレゼンテーションに利用できます。
サブスクリプションプランをダウングレードするにはどうすればよいですか?
サブスクリプションプランをダウングレードするにはどうすればよいですか?
レポートの編集と共有は誰ができますか?
レポートの編集と共有は誰ができますか?
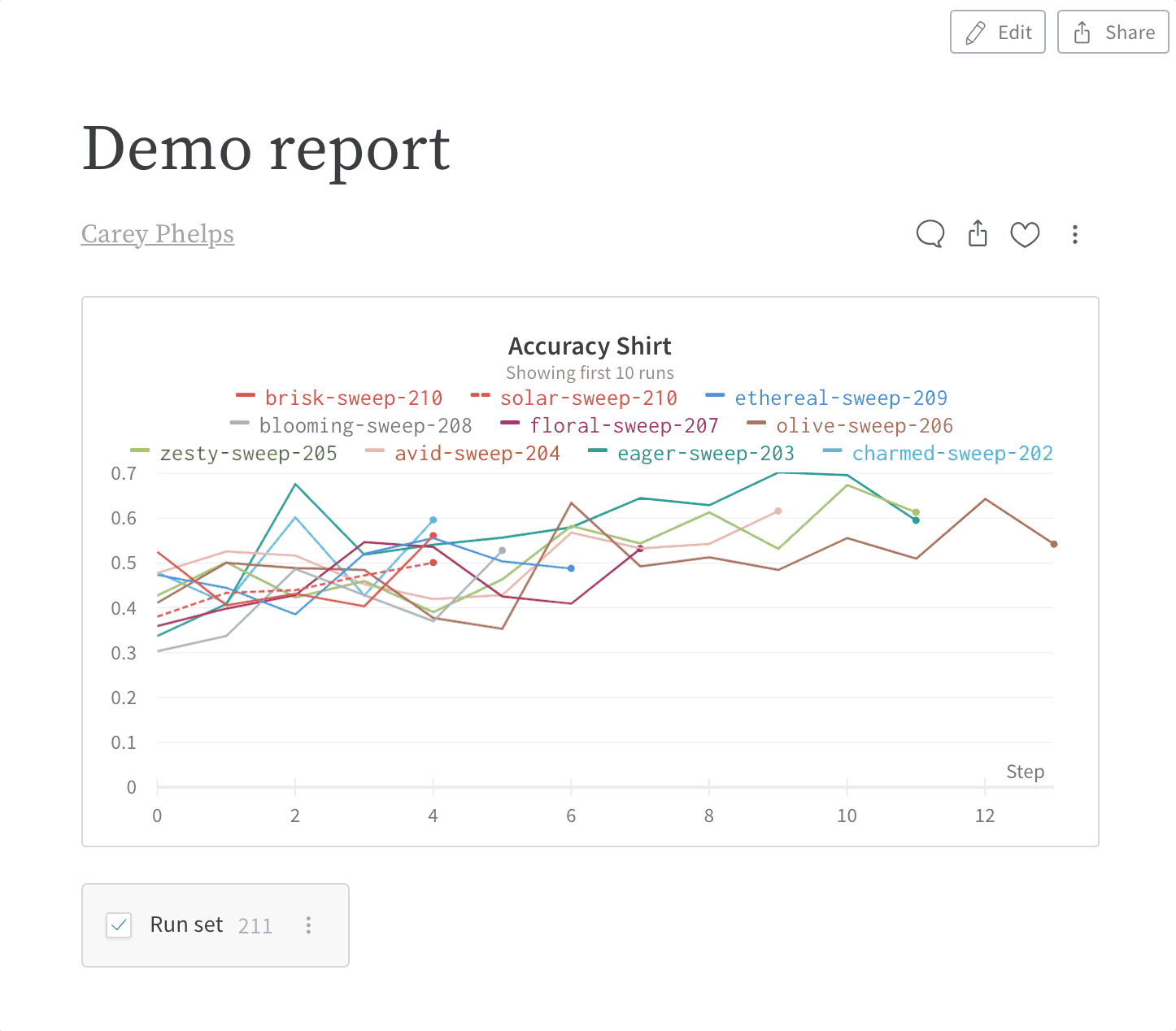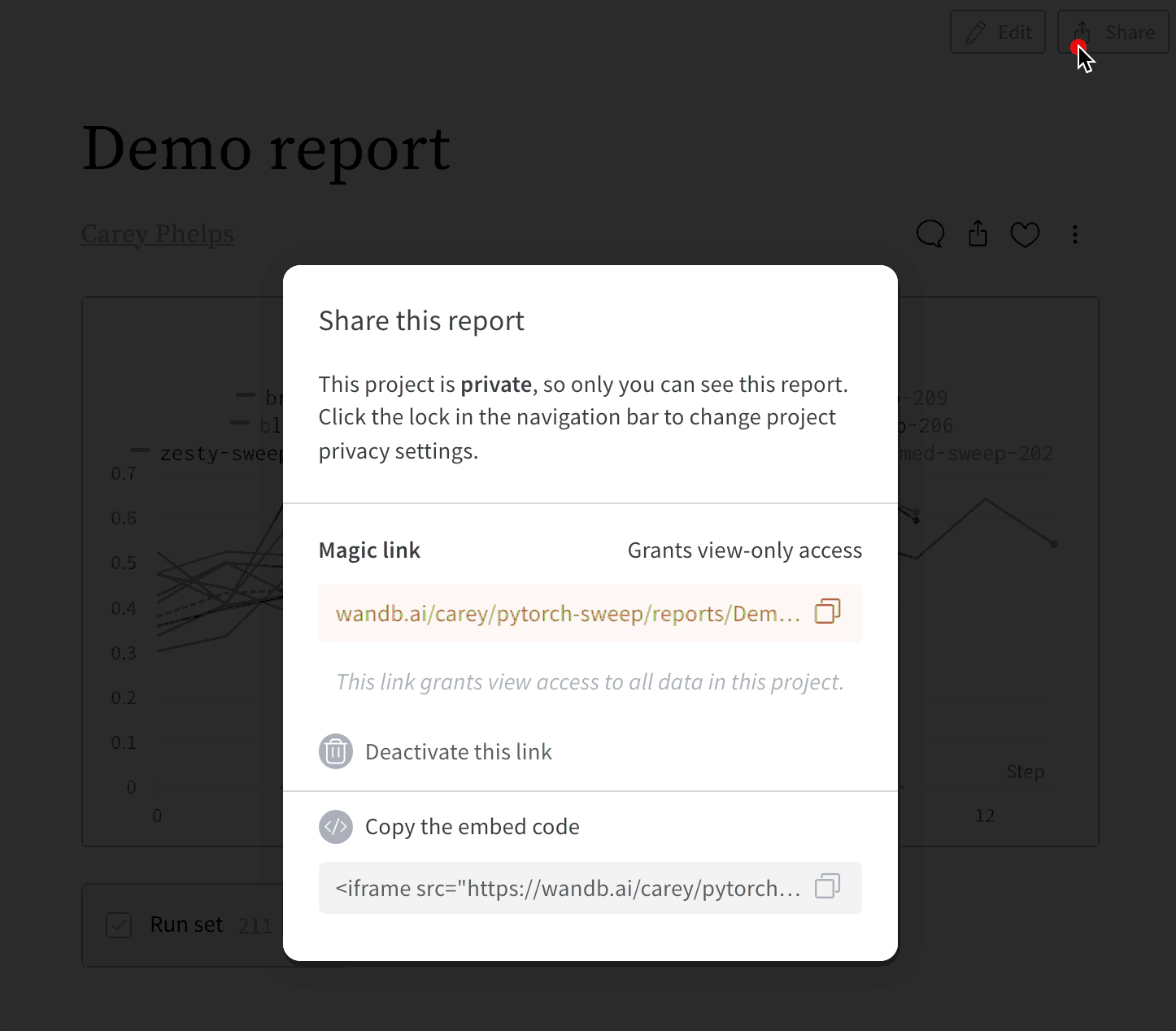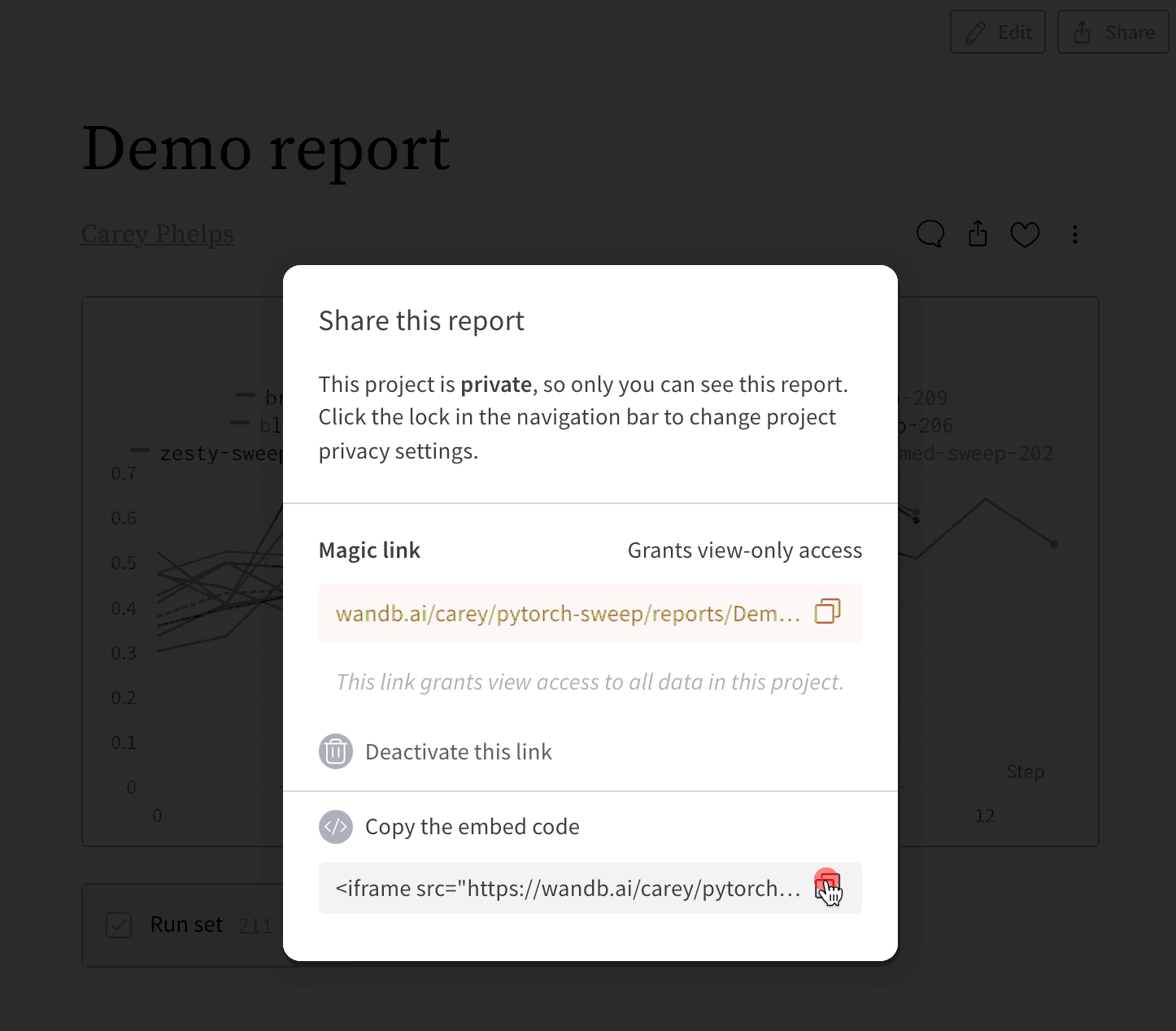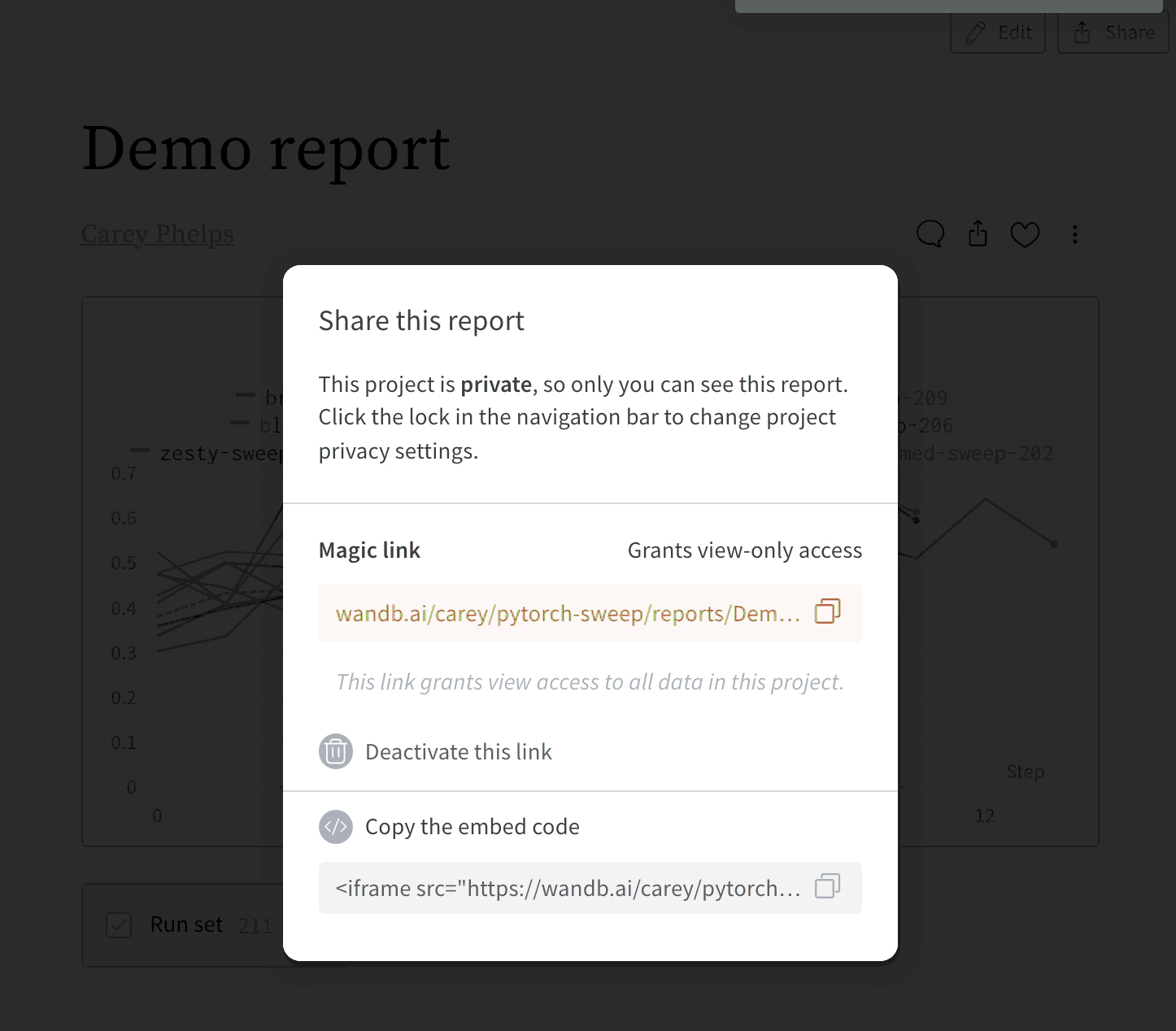
レポートの埋め込み
レポートの埋め込み
Sweeps でコードのログ記録を有効にするにはどうすればよいですか?
Sweeps でコードのログ記録を有効にするにはどうすればよいですか?
wandb.log_code() を追加します。これは、W&B プロフィール設定でコードのログ記録が有効になっている場合でも必要です。高度なコードログ記録については、こちらの wandb.log_code() ドキュメント を参照してください。環境変数は wandb.init() に渡されたパラメータを上書きしますか?
環境変数は wandb.init() に渡されたパラメータを上書きしますか?
wandb.init に渡された引数は環境変数を上書きします。環境変数が設定されていない場合にシステムデフォルト以外のデフォルトディレクトリーを設定するには、wandb.init(dir=os.getenv("WANDB_DIR", my_default_override)) を使用してください。`Est. Runs` カラムとは何ですか?
`Est. Runs` カラムとは何ですか?


expected_run_count 属性を使用します:W&B 組織から Users のリストをエクスポートするにはどうすればよいですか?
W&B 組織から Users のリストをエクスポートするにはどうすればよいですか?
W&B でこれらの Version ID や ETag を取得するにはどうすればよいですか?
W&B でこれらの Version ID や ETag を取得するにはどうすればよいですか?
コードがクラッシュした際、どのファイルをチェックすべきですか?
コードがクラッシュした際、どのファイルをチェックすべきですか?
wandb/run-<date>_<time>-<run-id>/logs にある debug.log と debug-internal.log を確認してください。Filestream rate limit exceeded エラーを解決するにはどうすればよいですか?
Filestream rate limit exceeded エラーを解決するにはどうすればよいですか?
- ログの記録頻度を減らすか、ログをバッチ処理して API リクエストを削減します。
- API リクエストが集中しないよう、実験の開始時間をずらします。
- W&B ステータスアップデート を確認し、サーバー側の一時的な問題が原因でないことを確認します。
- 実験設定の詳細を添えて W&B サポート (support@wandb.com) に連絡し、レート制限の引き上げを依頼してください。
不要なレポートをフィルタリングして削除する
不要なレポートをフィルタリングして削除する
自分の APIキー はどこにありますか?
自分の APIキー はどこにありますか?
- Organization admins can find or list API keys for all organization users and service accounts.
- Team admins can find or list API keys for service accounts in teams they administer.
- Non-admin users can find or list their own API keys.
- Personal API key
- Service account API key
- Log in to W&B, click your user profile icon, then click User Settings.
- Scroll to the API Keys section.
Sweep のベスト Run から Artifact を見つけるにはどうすればよいですか?
Sweep のベスト Run から Artifact を見つけるにはどうすればよいですか?
Run によってログ記録または使用された Artifacts を見つけるには?Artifact を作成または使用した Runs を見つけるには?
Run によってログ記録または使用された Artifacts を見つけるには?Artifact を作成または使用した Runs を見つけるには?
- Artifact から
- Run から
ブーリアン(真偽値)変数をハイパーパラメーターとしてフラグ指定できますか?
ブーリアン(真偽値)変数をハイパーパラメーターとしてフラグ指定できますか?
${args_no_boolean_flags} マクロを使用することで、ハイパーパラメーターをブーリアンフラグとして渡すことができます。このマクロは、ブーリアンパラメータを自動的にフラグとして含めます。param が True の場合、コマンドは --param を受け取ります。param が False の場合、フラグは省略されます。スムージングアルゴリズムにはどのような式を使用していますか?
スムージングアルゴリズムにはどのような式を使用していますか?
隠されている非常に便利な機能はどこで見つかりますか?
隠されている非常に便利な機能はどこで見つかりますか?
グラフに何も表示されないのはなぜですか?
グラフに何も表示されないのはなぜですか?
wandb.log 呼び出しがまだ実行されていません。これは、Run が 1 ステップの完了に長い時間を要している場合に発生することがあります。データのログ記録を早めるには、エポックの最後だけでなく、エポック内に複数回ログを記録するようにしてください。同じグループ内の各 Run の色を変更できますか?
同じグループ内の各 Run の色を変更できますか?
'Group' 機能を使わずに Runs をグループ化できますか?
'Group' 機能を使わずに Runs をグループ化できますか?
Group ボタンを使用して行えます。`wandb` ファイルのローカルな場所を定義するにはどうすればよいですか?
`wandb` ファイルのローカルな場所を定義するにはどうすればよいですか?
WANDB_DIR=<path>またはwandb.init(dir=<path>): トレーニングスクリプト用に作成されるwandbフォルダーの場所を制御します。デフォルトは./wandbです。このフォルダーには Run のデータとログが保存されます。WANDB_ARTIFACT_DIR=<path>またはwandb.Artifact().download(root="<path>"): Artifacts がダウンロードされる場所を制御します。デフォルトは./artifactsです。WANDB_CACHE_DIR=<path>:wandb.Artifactを呼び出した際に Artifacts が作成・保存される場所です。デフォルトは~/.cache/wandbです。WANDB_CONFIG_DIR=<path>: 設定ファイルが保存される場所です。デフォルトは~/.config/wandbです。WANDB_DATA_DIR=<PATH>: アップロード中に Artifacts をステージングするために使用される場所を制御します。デフォルトは~/.cache/wandb-data/です。
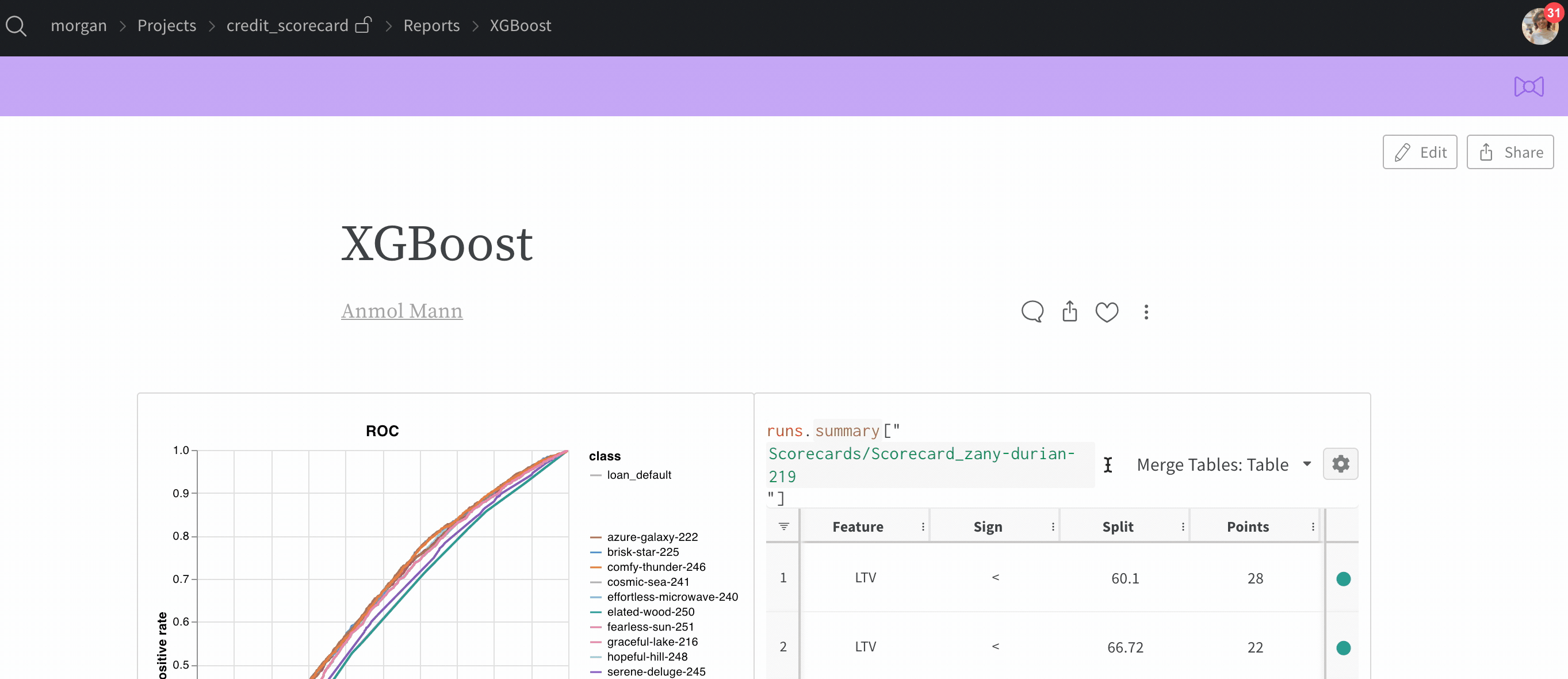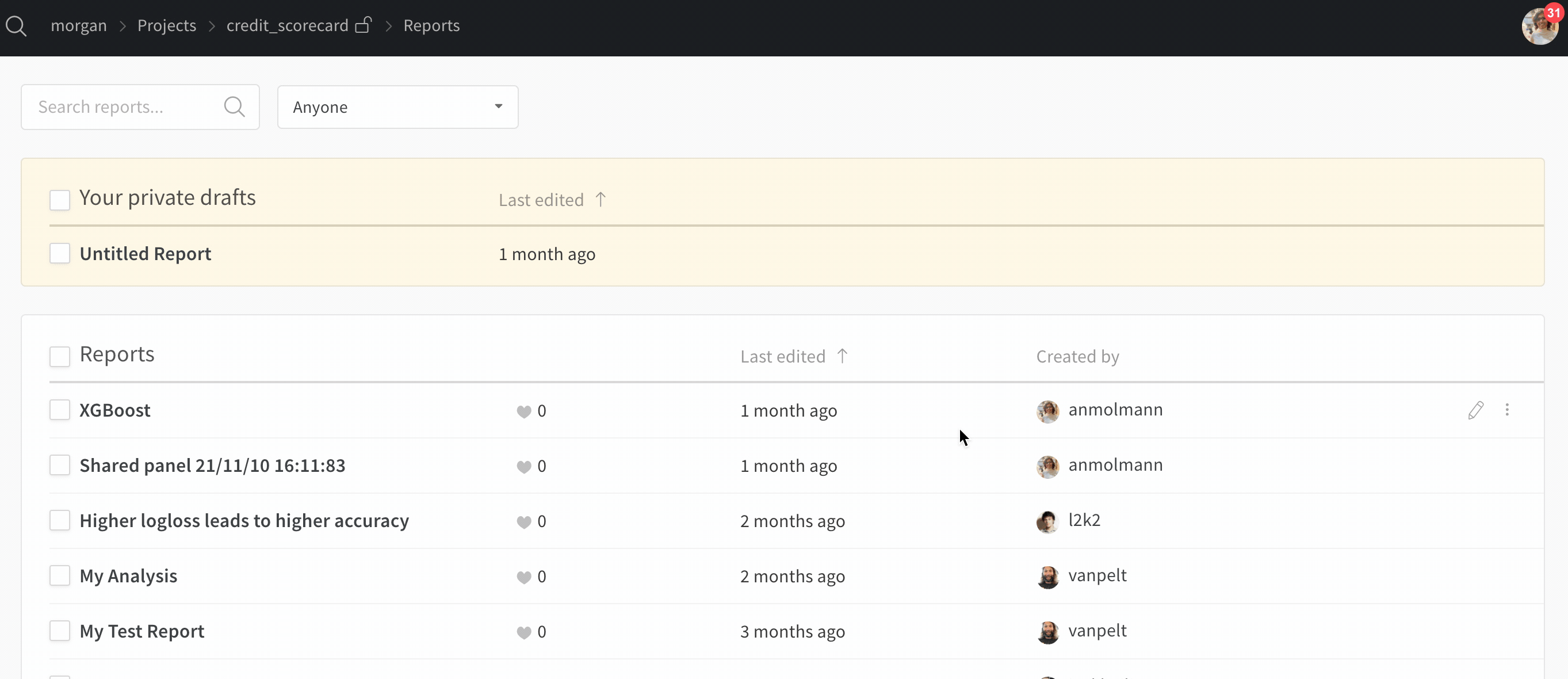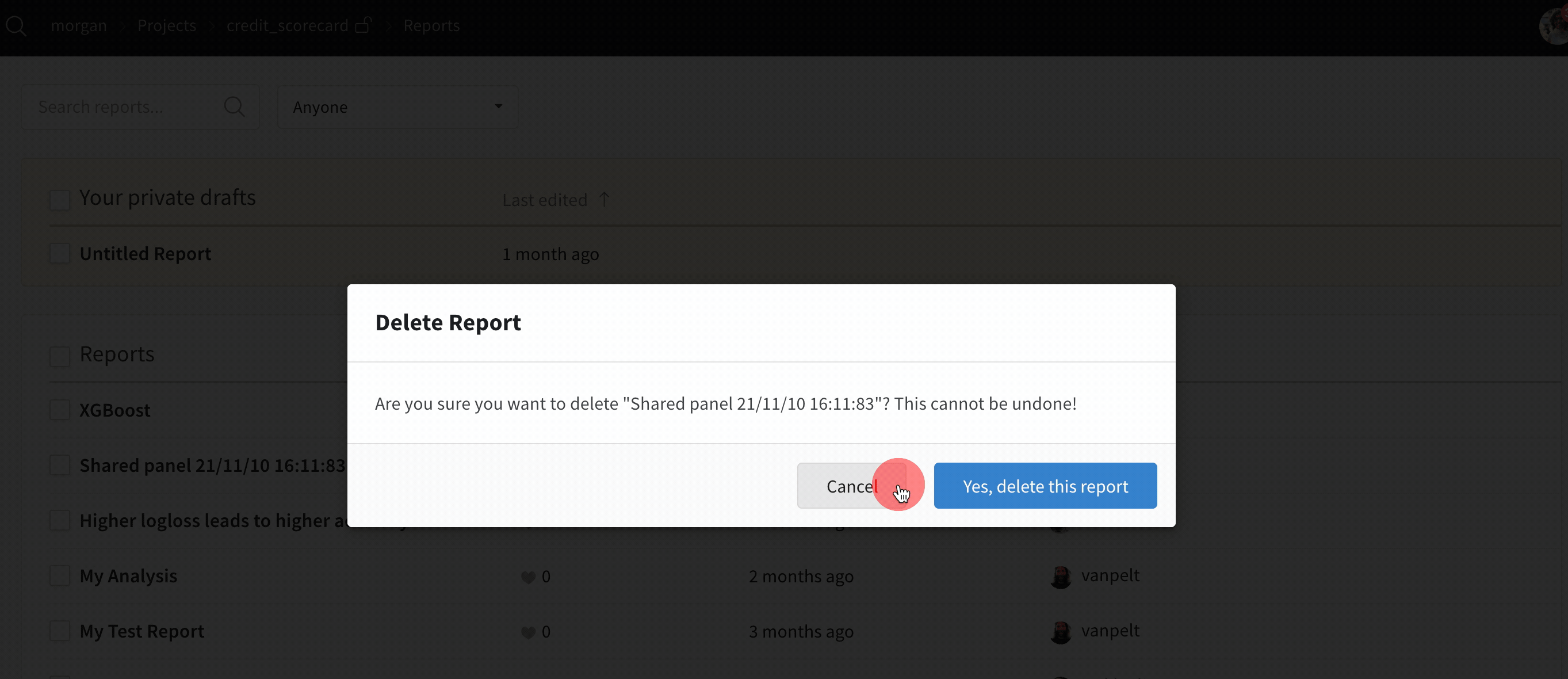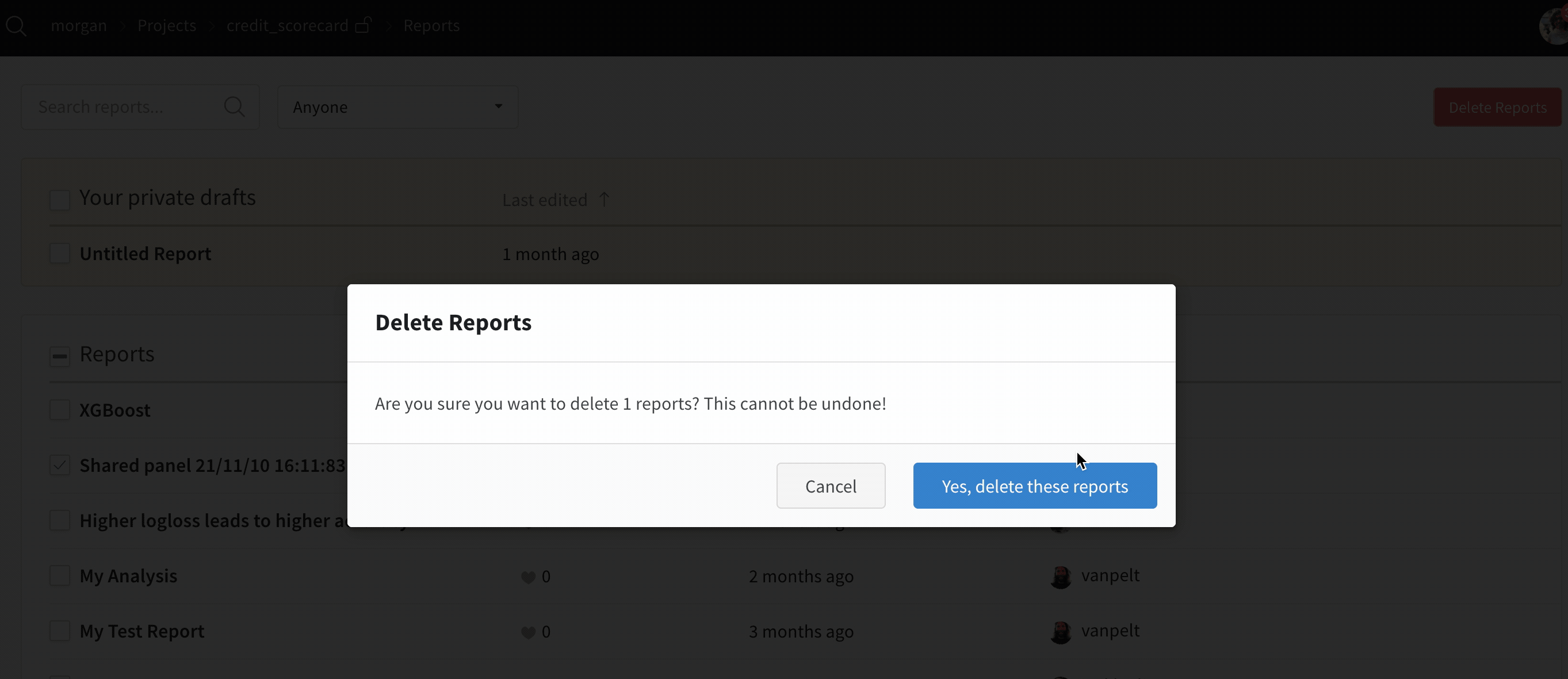
一度に 1 つずつではなく、一括で複数の Runs を削除するにはどうすればよいですか?
一度に 1 つずつではなく、一括で複数の Runs を削除するにはどうすればよいですか?
ユーザーアカウントを削除するにはどうすればよいですか?
ユーザーアカウントを削除するにはどうすればよいですか?
W&B サーバーにログインするにはどうすればよいですか?
W&B サーバーにログインするにはどうすればよいですか?
- 環境変数
WANDB_BASE_URLをサーバー URL に設定します。 wandb loginの--hostフラグをサーバー URL に設定します。
システムメトリクスのログ記録頻度を変更するにはどうすればよいですか?
システムメトリクスのログ記録頻度を変更するにはどうすればよいですか?
_stats_sampling_interval を秒数(float 型)で指定します。デフォルトは 10.0 です。`AttributeError: module 'wandb' has no attribute ...` のようなエラーを修正するにはどうすればよいですか?
`AttributeError: module 'wandb' has no attribute ...` のようなエラーを修正するにはどうすればよいですか?
wandb をインポートする際に AttributeError: module 'wandb' has no attribute 'init' や AttributeError: module 'wandb' has no attribute 'login' などのエラーが発生する場合、wandb がインストールされていないかインストールが壊れていますが、現在の作業ディレクトリーに wandb ディレクトリーが存在しています。これを修正するには、wandb をアンインストールし、そのディレクトリーを削除してから、wandb をインストールし直してください:Files タブに表示されないファイルを見るにはどうすればよいですか?
Files タブに表示されないファイルを見るにはどうすればよいですか?
`resume='must' but run (<run_id>) doesn't exist` エラーを修正するにはどうすればよいですか?
`resume='must' but run (<run_id>) doesn't exist` エラーを修正するにはどうすればよいですか?
resume='must' but run (<run_id>) doesn't exist というエラーが発生する場合、再開しようとしている Run がプロジェクトまたはエンティティ内に存在しません。正しいインスタンスにログインしていること、およびプロジェクトとエンティティが設定されていることを確認してください:wandb login --relogin を実行して、認証されているか確認してください。LaTeX の組み込み
LaTeX の組み込み
/ を押し、インライン数式タブに移動して LaTeX コンテンツを挿入します。W&B Inference での Invalid Authentication (401) エラーを修正するには?
W&B Inference での Invalid Authentication (401) エラーを修正するには?
APIキー の確認
- ユーザー設定 で新しい APIキー を作成します。
- APIキー を安全に保管してください。
プロジェクト設定の確認
プロジェクトが<your-team>/<your-project> の形式で正しく記述されているか確認してください:Python の例:よくある間違い
- チーム名の代わりに個人エンティティを使用している
- チーム名またはプロジェクト名のスペルミス
- チームとプロジェクトの間のスラッシュ(/)の欠落
- 期限切れまたは削除された APIキー の使用
まだ解決しない場合
- W&B アカウントにチームとプロジェクトが存在することを確認してください
- 指定したチームへのアクセス権があることを確認してください
- 現在のキーが機能しない場合は、新しい APIキー を作成してみてください
W&B Inference エラーを処理するためのベストプラクティスは何ですか?
W&B Inference エラーを処理するためのベストプラクティスは何ですか?
1. 常にエラーハンドリングを実装する
API 呼び出しを try-except ブロックで囲みます:2. 指数バックオフを伴うリトライロジックを使用する
3. 使用状況の監視
- W&B 請求(Billing)ページでクレジット使用量を追跡します。
- 制限に達する前にアラートを設定します。
- アプリケーションで API 使用状況をログに記録します。
4. 特定のエラーコードの処理
5. 適切なタイムアウトの設定
ユースケースに合わせて合理的なタイムアウトを設定してください:その他のヒント
- デバッグのためにタイムスタンプ付きでエラーを記録します。
- 並行処理をより良く扱うために非同期(async)操作を使用します。
- 本番システムにはサーキットブレーカーを実装します。
- 必要に応じてレスポンスをキャッシュし、API 呼び出しを削減します。
W&B Inference でクォータ不足エラー (402) が発生するのはなぜですか?
W&B Inference でクォータ不足エラー (402) が発生するのはなぜですか?
- W&B 請求(Billing)ページでクレジット残高を確認してください。
- クレジットを追加購入するか、プランをアップグレードしてください。
- サポート に制限の引き上げを依頼してください。
W&B Inference で国または地域がサポートされていないと言われるのはなぜですか?
W&B Inference で国または地域がサポートされていないと言われるのはなぜですか?
発生の理由
W&B Inference は、コンプライアンスおよび規制要件により地理的な制限があります。サービスは、サポートされている地理的な場所からのみアクセス可能です。対処法
-
利用規約の確認
- サポートされている場所の最新リストについては、利用規約 を確認してください。
-
サポートされている場所からの利用
- サポートされている国または地域にいるときにサービスにアクセスしてください。
- サポートされている場所にある組織のリソースの使用を検討してください。
-
担当チームへの連絡
- エンタープライズプランをご利用の場合は、担当の Account Executive にオプションを相談できます。
- 組織によっては特別な取り決めがある場合があります。
エラーの詳細
このエラーが表示される場合:W&B Inference でレート制限エラー (429) が発生するのはなぜですか?
W&B Inference でレート制限エラー (429) が発生するのはなぜですか?
- 並列リクエストの数を減らします。
- リクエスト間に遅延を追加します。
- 指数バックオフを実装します。
- 注意:レート制限は W&B プロジェクトごとに適用されます。
レート制限を避けるためのベストプラクティス
-
指数バックオフを伴うリトライロジックの実装:
- 並列リクエストの代わりにバッチ処理を使用する
- W&B 請求(Billing)ページで利用状況を監視する
デフォルトの支出上限
- Pro アカウント: $6,000/月
- Enterprise アカウント: $700,000/年
W&B Inference でサーバーエラー (500, 503) が発生した場合の修正方法は?
W&B Inference でサーバーエラー (500, 503) が発生した場合の修正方法は?
エラータイプ
500 - Internal Server Error
メッセージ: “The server had an error while processing your request”これはサーバー側の一時的な内部エラーです。503 - Service Overloaded
メッセージ: “The engine is currently overloaded, please try again later”サービスが高トラフィックの状態にあります。サーバーエラーの処理方法
-
再試行する前に待機する
- 500 エラー: 30〜60 秒待機します。
- 503 エラー: 60〜120 秒待機します。
-
指数バックオフを使用する
-
適切なタイムアウトの設定
- HTTP クライアントのタイムアウト値を増やします。
- 処理を改善するために非同期操作を検討してください。
サポートに連絡すべきタイミング
以下の場合、サポートに連絡してください:- エラーが 10 分以上続く場合
- 特定の時間帯に失敗するパターンが見られる場合
- エラーメッセージに追加の詳細が含まれている場合
- エラーメッセージとコード
- エラーが発生した時刻
- コードスニペット(APIキー は削除してください)
- W&B のエンティティ名とプロジェクト名
wandb での Run 初期化タイムアウトエラーを解決するには?
wandb での Run 初期化タイムアウトエラーを解決するには?
- 初期化の再試行: Run を再開してみてください。
- ネットワーク接続の確認: 安定したインターネット接続を確認してください。
- wandb バージョンの更新: 最新バージョンの wandb をインストールしてください。
- タイムアウト設定の引き上げ:
WANDB_INIT_TIMEOUT環境変数を変更します: - デバッグの有効化: 詳細なログを取得するために
WANDB_DEBUG=trueおよびWANDB_CORE_DEBUG=trueを設定します。 - 設定の検証: APIキー とプロジェクト設定が正しいか確認してください。
- ログの確認: エラーの詳細について
debug.log、debug-internal.log、debug-core.log、およびoutput.logを検査してください。
InitStartError: Error communicating with wandb process
InitStartError: Error communicating with wandb process
- Linux および OS X
- Google Colab
テーブルを挿入するにはどうすればよいですか?
テーブルを挿入するにはどうすればよいですか?
gcc のない環境で wandb Python ライブラリをインストールするにはどうすればよいですか?
gcc のない環境で wandb Python ライブラリをインストールするにはどうすればよいですか?
wandb のインストール中に以下のようなエラーが発生した場合:psutil をインストールしてください。お使いの Python バージョンと OS に適したものを https://pywharf.github.io/pywharf-pkg-repo/psutil で確認してください。例えば、Linux 上の Python 3.8 に psutil をインストールする場合:psutil のインストール後、pip install wandb を実行して wandb のインストールを完了させます。W&B をプロジェクトに統合したいのですが、画像やメディアをアップロードしたくない場合は?
W&B をプロジェクトに統合したいのですが、画像やメディアをアップロードしたくない場合は?
モデルのトレーニング中にインターネット接続が失われたらどうなりますか?
モデルのトレーニング中にインターネット接続が失われたらどうなりますか?
WANDB_MODE=offline を設定します。この設定では、メトリクスはハードドライブにローカル保存されます。後で wandb sync DIRECTORY を呼び出すことで、データをサーバーにストリーミングできます。W&B でチームに追加してもらうにはどうすればよいですか?
W&B でチームに追加してもらうにはどうすればよいですか?
- チーム管理者または管理権限を持つ人に連絡して、招待を依頼してください。
- 招待メールを確認し、指示に従ってチームに参加してください。
コードやデータセットの例を除いて、メトリクスのみを記録することはできますか?
コードやデータセットの例を除いて、メトリクスのみを記録することはできますか?
WANDB_DISABLE_CODEをtrueに設定して、すべてのコード追跡をオフにします。これにより、Git SHA や diff パッチの取得が行われなくなります。WANDB_IGNORE_GLOBSを*.patchに設定して、diff パッチのサーバーへの同期を停止します。ローカルには残るため、wandb restoreで適用可能です。
https://wandb.ai/<team>/settingsからチームの設定に移動します(<team>はチーム名)。- Privacy セクションまでスクロールします。
- Enable code saving by default のトグルをオフにします。
Run 名を Run ID と同じに設定できますか?
Run 名を Run ID と同じに設定できますか?
W&B でジョブを強制終了するにはどうすればよいですか?
W&B でジョブを強制終了するにはどうすればよいですか?
Ctrl+D を押します。1 つのスクリプトから複数の Runs を開始するにはどうすればよいですか?
1 つのスクリプトから複数の Runs を開始するにはどうすればよいですか?
wandb.init() をコンテキストマネージャーとして使用することです。これにより、Run が自動的に終了し、スクリプトで例外が発生した場合は失敗としてマークされます。run.finish() を呼び出すこともできます:複数のアクティブな Runs
wandb 0.19.10 以降では、reinit 設定を "create_new" に設定することで、複数の Run を同時にアクティブにできます。reinit="create_new" に関する詳細や、W&B インテグレーションに関する注意点については、1つのプロセスで複数のRunsを実行する を参照してください。ローカルインスタンスで問題が発生した際、どのファイルをチェックすべきですか?
ローカルインスタンスで問題が発生した際、どのファイルをチェックすべきですか?
Debug Bundle を確認してください。管理者は、右上隅の W&B アイコンから /system-admin ページに移動し、Debug Bundle を選択することで取得できます。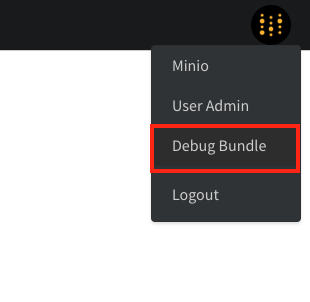
Run 完了後に追加のメトリクスをログに記録するにはどうすればよいですか?
Run 完了後に追加のメトリクスをログに記録するにはどうすればよいですか?
wandb.init() のグループパラメータを単一の実験内のすべてのプロセスで共通のユニークな値に設定します。Runs タブ ではテーブルがグループ ID でグループ化され、可視化が適切に機能します。このアプローチにより、並行する実験やトレーニング Run を行いながら、結果を 1 か所に記録できます。より単純なワークフローの場合は、resume=True と id=UNIQUE_ID を指定して wandb.init() を呼び出し、その後同じ id=UNIQUE_ID で再度 wandb.init() を呼び出します。通常通り run.log() や run.summary() でログを記録すれば、Run の値が適切に更新されます。既存の Run に Artifact をログ記録するにはどうすればよいですか?
既存の Run に Artifact をログ記録するにはどうすればよいですか?
継続的インテグレーション(CI)や内部ツールから起動された Runs をログに記録するにはどうすればよいですか?
継続的インテグレーション(CI)や内部ツールから起動された Runs をログに記録するにはどうすればよいですか?
WANDB_USERNAME または WANDB_USER_EMAIL 環境変数を設定してください。
値のリストをログに記録するにはどうすればよいですか?
値のリストをログに記録するにはどうすればよいですか?
wandb.Run.log() を使用して損失(losses)をログに記録するいくつかの方法を示しています。- 辞書(dictionary)を使用する場合
- ヒストグラムとして
最終評価精度のような、時間経過で変化しないメトリクスを記録するにはどうすればよいですか?
最終評価精度のような、時間経過で変化しないメトリクスを記録するにはどうすればよいですか?
run.log({'final_accuracy': 0.9}) を使用すると、最終精度が正しく更新されます。デフォルトでは、run.log({'final_accuracy': <value>}) は run.settings['final_accuracy'] を更新し、これが Runs テーブルに反映されます。バッチごととエポックごとに異なるメトリクスを記録したい場合は?
バッチごととエポックごとに異なるメトリクスを記録したい場合は?
2 つの異なる時間軸でメトリクスを記録できますか?
2 つの異なる時間軸でメトリクスを記録できますか?
batch や epoch のようなインデックスを記録してください。あるステップで wandb.Run.log()({'train_accuracy': 0.9, 'batch': 200}) を呼び出し、別のステップで wandb.Run.log()({'val_accuracy': 0.8, 'epoch': 4}) を呼び出します。UI では、各チャートに対して希望する値を X 軸として設定してください。特定のインデックスをデフォルトの X 軸として設定するには、Run.define_metric() を使用します。この例では、以下のコードを使用します:数百万ステップを W&B に記録するとどうなりますか?ブラウザではどのようにレンダリングされますか?
数百万ステップを W&B に記録するとどうなりますか?ブラウザではどのようにレンダリングされますか?
個人エンティティとチームエンティティのどちらに記録すべきですか?
個人エンティティとチームエンティティのどちらに記録すべきですか?
共有マシンで正しい W&B ユーザーとしてログを記録するには?
共有マシンで正しい W&B ユーザーとしてログを記録するには?
WANDB_API_KEY 環境変数を設定することで、Runs が正しい W&B アカウントに記録されるようにします。環境でソース指定されている場合、この変数はログイン時に正しい認証情報を提供します。または、スクリプト内で直接環境変数を設定することもできます。コマンド export WANDB_API_KEY=X を実行してください(X はあなたの APIキー に置き換えてください)。APIキー は wandb.ai/settings で作成できます。ログの記録はトレーニングをブロックしますか?
ログの記録はトレーニングをブロックしますか?
wandb.log 関数はローカルファイルに 1 行書き込むだけで、ネットワーク呼び出しをブロックしません。wandb.init を呼び出すと、同じマシン上で新しいプロセスが開始されます。このプロセスがファイルシステムの変更を監視し、ウェブサービスと非同期に通信するため、ローカル操作は中断されることなく継続されます。ログ記録をオフにするにはどうすればよいですか?
ログ記録をオフにするにはどうすればよいですか?
wandb offline は環境変数 WANDB_MODE=offline を設定し、リモートの W&B サーバーへのデータ同期を防ぎます。この操作はすべてのプロジェクトに影響し、W&B サーバーへのデータログ記録を停止します。警告メッセージを抑制するには、以下のコードを使用してください:特定の文字を含むメトリクスをソートやフィルタリングできないのはなぜですか?
特定の文字を含むメトリクスをソートやフィルタリングできないのはなぜですか?
有効なメトリクス名
- 使用可能な文字: 英文字 (A-Z, a-z)、数字 (0-9)、アンダースコア (_)
- 先頭の文字: 名前は英文字またはアンダースコアで始まる必要があります
- パターン: メトリクス名は
/^[_a-zA-Z][_a-zA-Z0-9]*$/に一致する必要があります
例
有効なメトリクス名:推奨される解決策
無効な文字をアンダースコアなどの有効な文字に置き換えてください:"test acc"の代わりに"test_acc""loss-train"の代わりに"loss_train""acc,val"の代わりに"acc_val"
Teams プランに月額サブスクリプションのオプションはありますか?
Teams プランに月額サブスクリプションのオプションはありますか?
Run をあるプロジェクトから別のプロジェクトに移動することは可能ですか?
Run をあるプロジェクトから別のプロジェクトに移動することは可能ですか?
- 移動したい Run があるプロジェクトページに移動します。
- Runs タブをクリックして Runs テーブルを開きます。
- 移動する Runs を選択します。
- Move ボタンをクリックします。
- 移動先のプロジェクトを選択し、操作を確定します。
wandb artifact get SDK コマンドや Api.artifact API を使用して Artifact をダウンロードし、その後 wandb artifact put または Api.artifact API を使用してアップロードしてください。異なる Runs を選択した複数のチャートを作成するには?
異なる Runs を選択した複数のチャートを作成するには?
- 複数のパネルグリッドを作成します。
- 各パネルグリッドに対してフィルタを適用し、希望する Run セットを選択します。
- パネルグリッド内で目的のチャートを生成します。
マルチプロセッシング(分散トレーニングなど)で wandb を使用するにはどうすればよいですか?
マルチプロセッシング(分散トレーニングなど)で wandb を使用するにはどうすればよいですか?
wandb.init() を実行していないプロセスから wandb メソッドを呼び出さないようにプログラムを構成してください。マルチプロセストレーニングは、以下の方法で管理します:- すべてのプロセスで
wandb.initを呼び出し、Group キーワード引数を使用して共有グループを作成します。各プロセスが独自の wandb run を持ち、UI 上でトレーニングプロセスがグループ化されます。 - 1 つのプロセスからのみ
wandb.initを呼び出し、multiprocessing queues を通じてログに記録するデータを渡します。
W&B は `multiprocessing` ライブラリを使用していますか?
W&B は `multiprocessing` ライブラリを使用していますか?
multiprocessing ライブラリを使用しています。以下のようなエラーメッセージは、問題が発生している可能性を示しています:if __name__ == "__main__": によるエントリポイントの保護を追加してください。これは、スクリプトから直接 W&B を実行する際に必要です。W&B Sweep の一部としてすべてのハイパーパラメーターの値を提供する必要がありますか?デフォルトを設定できますか?
W&B Sweep の一部としてすべてのハイパーパラメーターの値を提供する必要がありますか?デフォルトを設定できますか?
(run.config()) を使用して、スイープ設定からハイパーパラメーターの名前と値にアクセスできます。スイープ以外の Run の場合は、wandb.init() の config 引数に辞書を渡すことで wandb.Run.config() の値を設定します。スイープでは、wandb.init() に提供された設定はデフォルト値として機能し、スイープによって上書きされる可能性があります。明示的な動作をさせるには rwandb.Run.config.setdefaults() を使用します。以下のコードスニペットは両方の方法を示しています:- wandb.init()
- config.setdefaults()
複数のメトリクスを最適化する
複数のメトリクスを最適化する
W&B UI でログに記録されたチャートやメディアを整理するにはどうすればよいですか?
W&B UI でログに記録されたチャートやメディアを整理するにはどうすればよいですか?
/ 文字がログに記録されたパネルを区切ります。デフォルトでは、ログ項目の名前の / より前の部分が「Panel Section」と呼ばれるパネルのグループを定義します。/ で区切られたすべてのセグメントに基づいてパネルのグループ化を調整できます。'overflows maximum values of a signed 64 bits integer' エラーを修正するには?
'overflows maximum values of a signed 64 bits integer' エラーを修正するには?
?workspace=clear を追加して Enter キーを押してください。これにより、プロジェクトページのワークスペースのクリアされたバージョンが表示されます。クラス属性を wandb.Run.log() に渡すとどうなりますか?
クラス属性を wandb.Run.log() に渡すとどうなりますか?
wandb.Run.log() に渡すのは避けてください。ネットワーク呼び出しが実行される前に属性が変更される可能性があります。メトリクスをクラス属性として保存する場合は、ディープコピー(deep copy)を使用して、ログに記録されるメトリクスが wandb.Run.log() 呼び出し時点の属性値と一致するようにしてください。メトリクスをステップごとにプロットするのではなく、最大値をプロットすることは可能ですか?
メトリクスをステップごとにプロットするのではなく、最大値をプロットすることは可能ですか?
プロジェクトのプライバシーを変更するにはどうすればよいですか?
プロジェクトのプライバシーを変更するにはどうすればよいですか?
- W&B アプリで、プロジェクト内の任意のページから左ナビゲーションの Overview をクリックします。
- 右上の Edit をクリックします。
-
Project visibility に新しい値を選択します:
- Team (デフォルト): チームメンバーのみがプロジェクトの閲覧と編集が可能です。
- Restricted: 招待されたメンバーのみがプロジェクトにアクセスでき、パブリックアクセスはオフになります。
- Open: 誰でも Runs の送信や Reports の作成ができますが、編集できるのはチームメンバーのみです。教室での利用、公開ベンチマークコンペティション、その他の一時的なコンテキストにのみ適しています。
-
Public: 誰でもプロジェクトを閲覧できますが、編集できるのはチームメンバーのみです。
W&B 管理者が Public 可視化をオフにしている場合、これを選択することはできません。代わりに閲覧専用の W&B Report を共有するか、W&B 組織の管理者に相談してください。
- Save をクリックします。
'Failed to query for notebook' エラーへの対処法は?
'Failed to query for notebook' エラーへの対処法は?
"Failed to query for notebook name, you can set it manually with the WANDB_NOTEBOOK_NAME environment variable," というエラーメッセージが表示された場合は、環境変数を設定することで解決できます。いくつかの方法があります:- ノートブック内
- Python
スクリプト内でランダムな Run 名を取得するにはどうすればよいですか?
スクリプト内でランダムな Run 名を取得するにはどうすればよいですか?
.save() メソッドを呼び出して現在の Run を保存します。Run オブジェクトの name 属性を使用して名前を取得してください。Run と共に削除された Artifact を復元することは可能ですか?
Run と共に削除された Artifact を復元することは可能ですか?
削除された Runs を復元するにはどうすればよいですか?
削除された Runs を復元するにはどうすればよいですか?
- Project Overview ページに移動します。
- 右上隅にある 3 つのドットをクリックします。
- Undelete recently deleted runs を選択します。
- 復元できるのは、過去 7 日以内に削除された Runs のみです。
- 復元オプションがない場合は、W&B API を使用して手動でログをアップロードできます。
データの更新
データの更新
パスワードリセットメールが届かない場合、どうすればアカウントへのアクセスを回復できますか?
パスワードリセットメールが届かない場合、どうすればアカウントへのアクセスを回復できますか?
- 迷惑メールフォルダを確認する: メールがフィルタリングされていないか確認してください。
- メールアドレスの確認: アカウントに関連付けられた正しいメールアドレスであることを確認してください。
- SSO オプションを確認する: 利用可能な場合は「Google でサインイン」などのサービスを使用してください。
- サポートに連絡する: 問題が解決しない場合は、サポート (support@wandb.com) に連絡し、ユーザー名とメールアドレスを提供して支援を依頼してください。
管理者権限なしでチームスペースからプロジェクトを削除するにはどうすればよいですか?
管理者権限なしでチームスペースからプロジェクトを削除するにはどうすればよいですか?
- 現在の管理者にプロジェクトの削除を依頼してください。
- 管理者にプロジェクト管理のための一時的なアクセス権限を付与するよう依頼してください。
プロジェクト名を変更するにはどうすればよいですか?
プロジェクト名を変更するにはどうすればよいですか?
- Project overview に移動します。
- Edit Project をクリックします。
model-registryなどの保護されたプロジェクト名は変更できません。保護された名前に関する支援については、サポートにお問い合わせください。
期限切れのライセンスを更新するにはどうすればよいですか?
期限切れのライセンスを更新するにはどうすればよいですか?
Markdown から変換した後のレポートの見た目が異なります。
Markdown から変換した後のレポートの見た目が異なります。
WYSIWYG への変更後、レポートの動作が遅くなりました
WYSIWYG への変更後、レポートの動作が遅くなりました
レポートで Markdown を使用できますか?
レポートで Markdown を使用できますか?
W&B アカウントの完全な削除をリクエストするにはどうすればよいですか?
W&B アカウントの完全な削除をリクエストするにはどうすればよいですか?
グリッド検索(Grid Search)を再実行できますか?
グリッド検索(Grid Search)を再実行できますか?
アカウントのログイン問題を解決するにはどうすればよいですか?
アカウントのログイン問題を解決するにはどうすればよいですか?
- アクセスの確認: 正しいメールアドレスまたはユーザー名を使用しているか確認し、関連する Teams や Projects への所属を確認してください。
- ブラウザのトラブルシューティング:
- キャッシュデータの干渉を避けるため、シークレットウィンドウを使用してください。
- ブラウザのキャッシュをクリアしてください。
- 別のブラウザやデバイスからログインを試みてください。
- SSO と権限:
- ID プロバイダー (IdP) とシングルサインオン (SSO) の設定を確認してください。
- SSO を使用している場合は、適切な SSO グループに含まれていることを確認してください。
- 技術的な問題:
- 詳細なトラブルシューティングのために、特定のエラーメッセージをメモしてください。
- 問題が解決しない場合は、サポートチームに詳細な支援を求めてください。
Run をログ記録する際の権限エラーを解決するには?
Run をログ記録する際の権限エラーを解決するには?
- エンティティ名とプロジェクト名の確認: コード内の W&B エンティティ名とプロジェクト名の綴り、大文字小文字が正しいか確認してください。
- 権限の確認: 管理者によって必要な権限が付与されていることを確認してください。
- ログイン情報の確認: 正しい W&B アカウントにログインしていることを確認してください。以下のコードで Run を作成してテストしてください:
- APIキー の設定:
WANDB_API_KEY環境変数を使用してください: - ホスト情報の確認: カスタムデプロイメントの場合は、ホスト URL を設定してください:
W&B で Run を再開する際に resume パラメータを使用するには?
W&B で Run を再開する際に resume パラメータを使用するには?
resume パラメータを使用するには、wandb.init() で entity、project、および id を指定した上で、resume 引数を設定します。resume 引数は "must" または "allow" の値を受け入れます。Python コードを使用してスイープを再開するにはどうすればよいですか?
Python コードを使用してスイープを再開するにはどうすればよいですか?
wandb.agent() 関数に sweep_id を渡します。Artifact に保持ポリシーや有効期限ポリシーを設定するにはどうすればよいですか?
Artifact に保持ポリシーや有効期限ポリシーを設定するにはどうすればよいですか?
アクセス権のローテーションや取り消しを行うには?
アクセス権のローテーションや取り消しを行うには?
'Run Finished' アラートはノートブックで機能しますか?
'Run Finished' アラートはノートブックで機能しますか?
run.alert() を使用してください。ローカルでは正常にトレーニングされているのに、W&B で Run が crashed とマークされるのはなぜですか?
ローカルでは正常にトレーニングされているのに、W&B で Run が crashed とマークされるのはなぜですか?
アカウントを持っていない人が Run の結果を見るには?
アカウントを持っていない人が Run の結果を見るには?
anonymous="allow" を指定してスクリプトを実行した場合:- 一時アカウントの自動作成: W&B はサインイン済みのアカウントを確認します。存在しない場合、W&B は新しい匿名アカウントを作成し、そのセッション用の APIキー を保存します。
- 迅速な結果ログ記録: ユーザーは繰り返しスクリプトを実行し、W&B ダッシュボードで即座に結果を確認できます。これらの未登録の匿名 Runs は 7 日間利用可能です。
- 有用なデータの登録: W&B で価値のある結果が見つかったら、ページ上部のバナーにあるボタンをクリックして、Run データを実際のアカウントに保存できます。登録しない場合、Run データは 7 日後に削除されます。
SLURM でスイープを実行するにはどうすればよいですか?
SLURM でスイープを実行するにはどうすればよいですか?
wandb agent --count 1 SWEEP_ID を実行してください。このコマンドは単一のトレーニングジョブを実行して終了するため、ハイパーパラメーター探索の並列性を活かしつつ、リソースリクエストのための実行時間予測が容易になります。wandb をオフラインで実行できますか?
wandb をオフラインで実行できますか?
- 環境変数
WANDB_MODE=offlineを設定し、インターネット接続なしでメトリクスをローカルに保存します。 - アップロードの準備ができたら、ディレクトリー内で
wandb initを実行してプロジェクト名を設定します。 wandb sync YOUR_RUN_DIRECTORYを使用して、メトリクスをクラウドサービスに転送し、ホストされたウェブアプリで結果にアクセスします。
wandb.init() 実行後に run.settings._offline または run.settings.mode を確認してください。1 つのプロジェクトにいくつの Runs を作成できますか?
1 つのプロジェクトにいくつの Runs を作成できますか?
UI 上では Run の状態が `crashed` ですが、マシン上ではまだ動作しています。データを取り戻すにはどうすればよいですか?
UI 上では Run の状態が `crashed` ですが、マシン上ではまだ動作しています。データを取り戻すにはどうすればよいですか?
wandb sync [PATH_TO_RUN] を実行してデータを復旧してください。Run へのパスは、wandb ディレクトリー内の、実行中の Run ID と一致するフォルダーです。同じメトリクスが複数回表示されるのはなぜですか?
同じメトリクスが複数回表示されるのはなぜですか?
number、string、bool、other(主に配列)、および Histogram や Image などの W&B データタイプです。この問題を避けるために、1 つのキーに対して 1 つのタイプのみを送信するようにしてください。メトリクス名は大文字と小文字を区別しません。"My-Metric" と "my-metric" のように、大文字小文字のみが異なる名前の使用は避けてください。コードを保存するにはどうすればよいですか?
コードを保存するにはどうすればよいですか?
wandb.init で save_code=True を使用すると、Run を起動したメインスクリプトまたはノートブックを保存できます。Run のすべてのコードを保存するには、Artifacts でコードをバージョン管理してください。以下の例はこのプロセスを示しています:Run に関連付けられた Git コミットを保存するにはどうすればよいですか?
Run に関連付けられた Git コミットを保存するにはどうすればよいですか?
wandb.init が呼び出されると、システムは自動的に Git 情報(リモートリポジトリのリンクや最新コミットの SHA など)を収集します。この情報は Run ページ に表示されます。この情報を表示するには、スクリプト実行時のカレント作業ディレクトリーが Git 管理下のフォルダー内にあることを確認してください。Git コミットと実験の実行に使用されたコマンドは、実行ユーザーには表示されますが、外部ユーザーからは隠されます。パブリックプロジェクトでも、これらの詳細はプライベートなままです。メトリクスをオフラインで保存し、後で W&B に同期することは可能ですか?
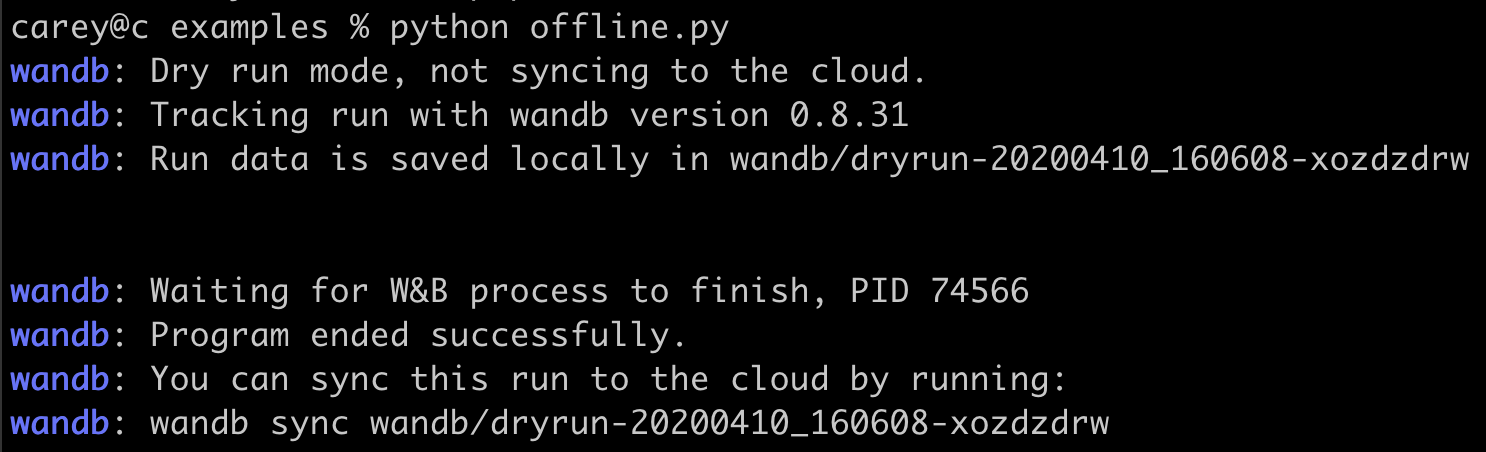
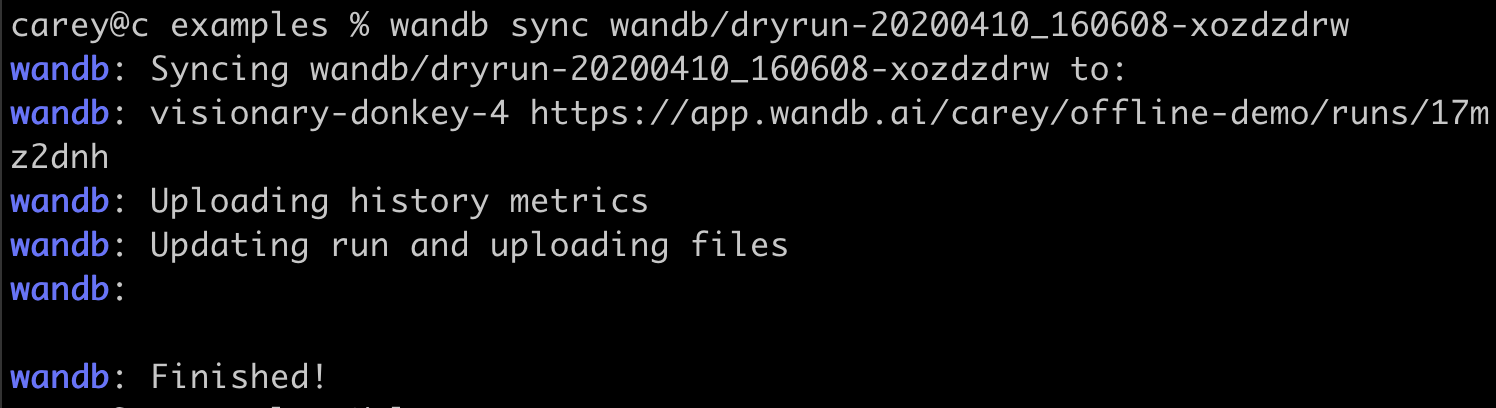
メトリクスをオフラインで保存し、後で W&B に同期することは可能ですか?
wandb.init はメトリクスをクラウドにリアルタイムで同期するプロセスを開始します。オフラインで使用する場合は、2 つの環境変数を設定してオフラインモードを有効にし、後で同期させることができます。以下の環境変数を設定してください:WANDB_API_KEY=$KEY($KEYは ユーザー設定 で作成した APIキー です)。WANDB_MODE="offline"。
組織の Bytes stored(保存済みバイト)、Bytes tracked(追跡済みバイト)、Tracked hours(追跡時間)を確認するには?
組織の Bytes stored(保存済みバイト)、Bytes tracked(追跡済みバイト)、Tracked hours(追跡時間)を確認するには?
https://wandb.ai/account-settings/<organization-name>/settingsで組織の設定に移動します。- Billing タブを選択します。
- Usage this billing period セクションで、View usage ボタンを選択します。
<> で囲まれた部分は、ご自身の組織名に置き換えてください。ログに記録したデータポイントよりも少ない数しか表示されないのはなぜですか?
ログに記録したデータポイントよりも少ない数しか表示されないのはなぜですか?
Step 以外の X 軸に対してメトリクスを可視化する場合、データポイントが少なく表示されることが予想されます。メトリクスが同期を保つには、同じ Step でログ記録される必要があります。サンプリング間の補間中には、同じ Step で記録されたメトリクスのみがサンプリングされます。ガイドラインメトリクスを単一の log() 呼び出しにまとめてください。例えば、次のようにする代わりに:log() 呼び出しで step の値が同じであることを確認してください。これにより、メトリクスが同じステップの下で記録され、一緒にサンプリングされます。step の値は、各呼び出しにおいて単調増加(monotonically increase)する必要があります。そうでない場合、step の値は無視されます。Microsoft Teams に Run アラートを送信するにはどうすればよいですか?
Microsoft Teams に Run アラートを送信するにはどうすればよいですか?
- Teams チャンネルのメールアドレスを設定する。 アラートを受信したい Teams チャンネル用のメールアドレスを作成します。
- W&B アラートメールを Teams チャンネルのメールアドレスに転送する。 W&B がメールでアラートを送信するように設定し、それらのメールを Teams チャンネルのメールアドレスに転送するように設定してください。
サービスアカウントとは何ですか?なぜ便利なのですか?
サービスアカウントとは何ですか?なぜ便利なのですか?
- ライセンスの消費なし: サービスアカウントはユーザーシートやライセンスを消費しません。
- 専用の APIキー: 自動化ワークフロー用の安全な認証情報。
- ユーザー属性(User attribution): オプションで自動化された Runs を特定のユーザーに紐付けることが可能。
- エンタープライズ対応: 大規模な本番自動化向けに構築されています。
- 委任された操作: サービスアカウントは、それを作成したユーザーまたは組織に代わって操作します。
WANDB_USERNAME または WANDB_USER_EMAIL を使用して、これらのマシンから起動された Runs にユーザー名を関連付けることができます。ベストプラクティスや詳細な設定手順を含むサービスアカウントの包括的な情報については、サービスアカウントを使用してワークフローを自動化する を参照してください。チームコンテキストでのサービスアカウントの振る舞いについては、Team Service Account Behavior を参照してください。To create a new team-scoped service account and API key:- In your team’s settings, click Service Accounts.
- Click New Team Service Account.
- Provide a name for the service account.
- Set Authentication Method to Generate API key (default). If you select Federated Identity, the service account cannot own API keys.
- Click Create.
- Find the service account you just created.
- Click the action menu (
...), then click Create API key. - Provide a name for the API key, then click Create.
- Copy the API key and store it securely.
- Click Done.
カスタムチャートに「ステップスライダー」を表示するにはどうすればよいですか?
カスタムチャートに「ステップスライダー」を表示するにはどうすればよいですか?
summaryTable ではなく historyTable を使用するように変更すると、カスタムチャートエディターに「Show step selector」オプションが表示されます。この機能には、ステップを選択するためのスライダーが含まれます。W&B の情報メッセージを消すにはどうすればよいですか?
W&B の情報メッセージを消すにはどうすればよいですか?
logging.ERROR に設定してエラーのみを表示させ、情報レベルのログ出力を抑制します。WANDB_QUIET を True に設定します。ログ出力を完全にオフにするには、環境変数 WANDB_SILENT を True に設定してください。ノートブックでは、wandb.login を実行する前に WANDB_QUIET または WANDB_SILENT を設定します:- ノートブック内
- Python
W&B はトレーニングを遅くしますか?
W&B はトレーニングを遅くしますか?
W&B はマルチテナント向けに SSO をサポートしていますか?
W&B はマルチテナント向けに SSO をサポートしていますか?
- ID プロバイダー上で Single Page Application (SPA) を作成します。
grant_typeをimplicitフローに設定します。- コールバック URI を
https://wandb.auth0.com/login/callbackに設定します。
Client ID と Issuer URL を添えて、カスタマーサクセスマネージャー (CSM) に連絡してください。W&B はこれらの詳細を使用して Auth0 接続を確立し、SSO を有効にします。wandb がターミナルや Jupyter ノートブックの出力に書き込むのを停止するにはどうすればよいですか?
wandb がターミナルや Jupyter ノートブックの出力に書き込むのを停止するにはどうすればよいですか?
WANDB_SILENT を true に設定してください。- Python
- ノートブック内
- コマンドライン
Run を削除してもストレージメーターが更新されないのはなぜですか?
Run を削除してもストレージメーターが更新されないのはなぜですか?
- 処理の遅延により、Run の削除直後にはストレージメーターが更新されません。
- バックエンドシステムが同期し、使用量の変化を正確に反映させるまでに時間がかかります。
- ストレージメーターが更新されない場合は、処理が完了するまでお待ちください。
wandb はどのようにログをストリーミングし、ディスクに書き込みますか?
wandb はどのようにログをストリーミングし、ディスクに書き込みますか?
WANDB_MODE=offline 設定をサポートし、ログ記録後の同期を可能にします。ターミナルでは、ローカル Run ディレクトリーへのパスを確認できます。このディレクトリーには、データストアとして機能する .wandb ファイルが含まれています。画像ログについては、W&B はクラウドストレージにアップロードする前に、media/images サブディレクトリーに画像を保存します。AWS Batch や ECS などのクラウドインフラで W&B Sweeps を使用できますか?
AWS Batch や ECS などのクラウドインフラで W&B Sweeps を使用できますか?
sweep_id を公開するには、これらのエージェントが sweep_id を読み取って実行するためのメソッドを実装してください。例えば、Amazon EC2 インスタンスを起動し、その上で wandb agent を実行します。SQS キューを使用して、複数の EC2 インスタンスに sweep_id をブロードキャストします。各インスタンスはキューから sweep_id を取得してプロセスを開始できます。Sweeps と SageMaker を併用できますか?
Sweeps と SageMaker を併用できますか?
requirements.txt ファイルを作成してください。認証と requirements.txt ファイルの設定に関する詳細は、SageMaker インテグレーション ガイドを参照してください。SageMaker と W&B を使用した感情分析器のデプロイについては、Deploy Sentiment Analyzer Using SageMaker and W&B チュートリアル をご覧ください。
同じマシンでアカウントを切り替えるにはどうすればよいですか?
同じマシンでアカウントを切り替えるにはどうすればよいですか?
システムメトリクスはどのくらいの頻度で収集されますか?
システムメトリクスはどのくらいの頻度で収集されますか?
チームとは何ですか?どこで詳細情報を確認できますか?
チームとは何ですか?どこで詳細情報を確認できますか?
コードのテスト時に wandb をオフにできますか?
コードのテスト時に wandb をオフにできますか?
wandb.init(mode="disabled") を使用するか、WANDB_MODE=disabled を設定してください。wandb.init(mode="disabled") を使用しても、W&B が WANDB_CACHE_DIR に Artifacts を保存するのを防ぐことはできません。トレーニングデータの追跡や保存は行われますか?
トレーニングデータの追跡や保存は行われますか?
wandb.Run.config.update(...) に渡します。wandb.Run.save() がローカルファイル名と共に呼び出されない限り、W&B はデータを保存しません。どのようなロール(役割)があり、それらの違いは何ですか?
どのようなロール(役割)があり、それらの違いは何ですか?
支払い方法を更新するにはどうすればよいですか?
支払い方法を更新するにはどうすればよいですか?
- プロフィールページに移動する: まず、ユーザープロフィールページに移動します。
- 組織(Organization)を選択する: アカウントセレクターから該当する組織を選択します。
- Billing 設定にアクセスする: Account の下にある Billing を選択します。
- 新しい支払い方法を追加する:
- Add payment method をクリックします。
- 新しいカードの詳細を入力し、それを primary(優先)な支払い方法にするオプションを選択します。
注意: 請求を管理するには、組織の請求管理者(billing admin)として割り当てられている必要があります。
レポートに CSV をアップロードする
レポートに CSV をアップロードする
wandb.Table 形式を使用してください。Python スクリプトで CSV を読み込み、それを wandb.Table オブジェクトとして記録します。この操作により、レポート内でデータがテーブルとしてレンダリングされます。レポートに画像をアップロードする
レポートに画像をアップロードする
/ を押し、Image オプションまでスクロールして、画像をレポートにドラッグアンドドロップしてください。
W&B チームメンバーは私のデータを見ることができますか?
W&B チームメンバーは私のデータを見ることができますか?
W&B で障害が発生していますか?
W&B で障害が発生していますか?
wandb.init はトレーニングプロセスにどのような影響を与えますか?
wandb.init はトレーニングプロセスにどのような影響を与えますか?
wandb.init() が実行されると、サーバー上に Run オブジェクトを作成するための API 呼び出しが行われます。メトリクスをストリーミングして収集するための新しいプロセスが開始され、プライマリプロセスは通常通り機能し続けることができます。スクリプトがローカルファイルに書き込む一方で、別のプロセスがシステムメトリクスを含むデータをサーバーにストリーミングします。ストリーミングをオフにするには、トレーニングディレクトリーから wandb off を実行するか、環境変数 WANDB_MODE を offline に設定してください。スイープの実行中に Python ファイルを編集するとどうなりますか?
スイープの実行中に Python ファイルを編集するとどうなりますか?
- スイープが使用している
train.pyスクリプトが変更された場合、スイープは元のtrain.pyを使い続けます。 train.pyスクリプトが参照しているファイル(helper.pyスクリプト内のヘルパー関数など)が変更された場合、スイープは更新されたhelper.pyを使い始めます。
Artifacts はどこにダウンロードされますか?また、それを制御するには?
Artifacts はどこにダウンロードされますか?また、それを制御するには?
artifacts/ フォルダーにダウンロードされます。場所を変更するには:-
wandb.Artifact().downloadにパスを渡します: -
WANDB_ARTIFACT_DIR環境変数 を設定します:
CSV 形式でのメトリクスエクスポートでステップが欠落しているのはなぜですか?
CSV 形式でのメトリクスエクスポートでステップが欠落しているのはなぜですか?
run.history API を使用してエクスポートされない場合があります。完全な Run History にアクセスするには、Parquet 形式を使用して Run History の Artifact をダウンロードしてください:これは Python でしか使えませんか?
これは Python でしか使えませんか?