1. W&B에 데이터 로그하기
먼저, 스크립트에서 데이터를 로그합니다. 하이퍼파라미터와 같이 트레이닝 시작 시점에 설정되는 단일 포인트의 경우 wandb.Run.config를 사용하세요. 시간에 따른 여러 포인트의 경우 wandb.Run.log()를 사용하고, 커스텀 2D 어레이는wandb.Table()로 로그합니다. 로그되는 키 하나당 최대 10,000개의 데이터 포인트를 로그하는 것을 권장합니다.
2. 쿼리 생성하기
시각화할 데이터를 로그했다면, 프로젝트 페이지로 이동하여+ 버튼을 클릭해 새 패널을 추가한 다음 Custom Chart를 선택하세요. 커스텀 차트 데모 워크스페이스에서 과정을 따라하실 수 있습니다.

쿼리 추가
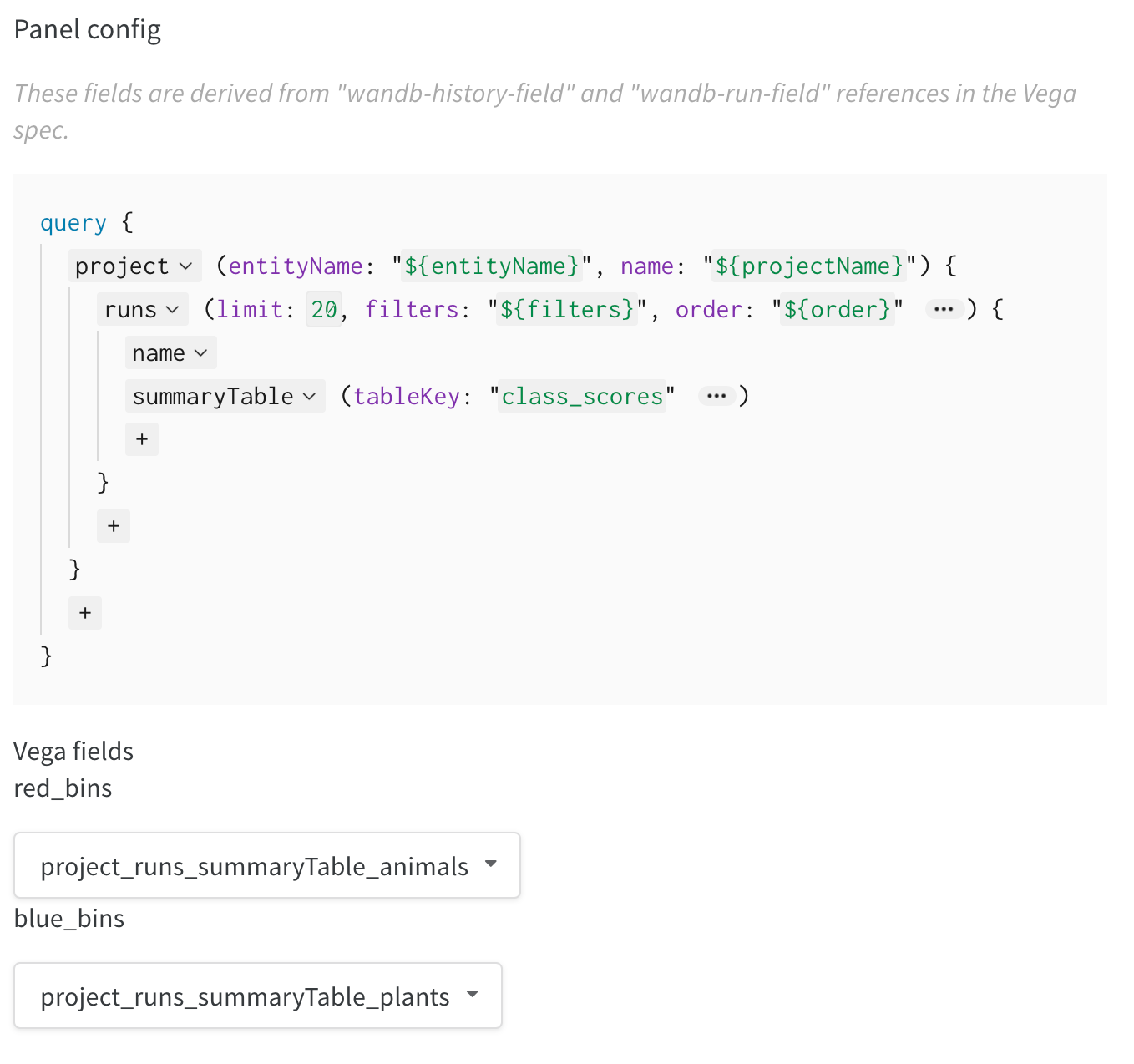
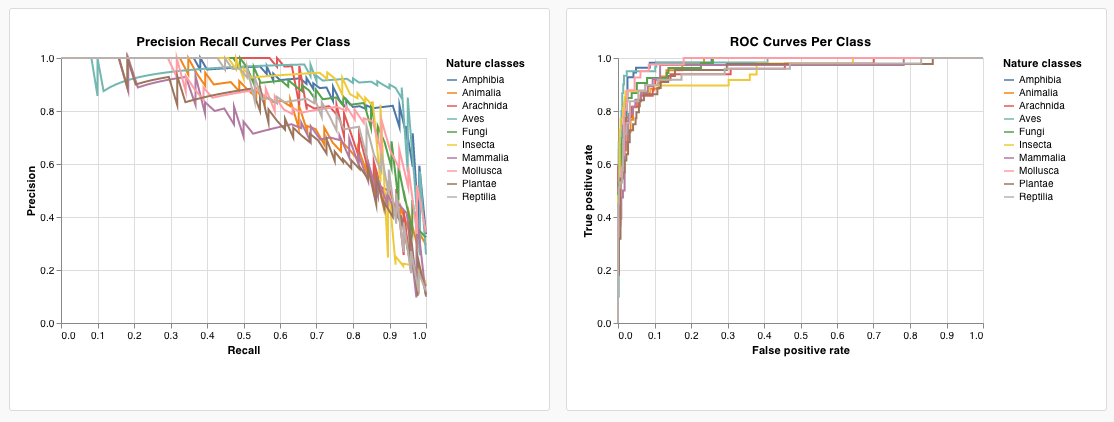
summary를 클릭하고historyTable을 선택하여 Run 기록에서 데이터를 가져오는 새 쿼리를 설정합니다.wandb.Table()을 로그할 때 사용한 키를 입력합니다. 위의 코드 조각에서는my_custom_table이었습니다. 예제 노트북에서 키는pr_curve와roc_curve입니다.
Vega 필드 설정
이제 쿼리가 이 컬럼들을 로드하므로, Vega 필드 드롭다운 메뉴에서 옵션으로 선택할 수 있습니다.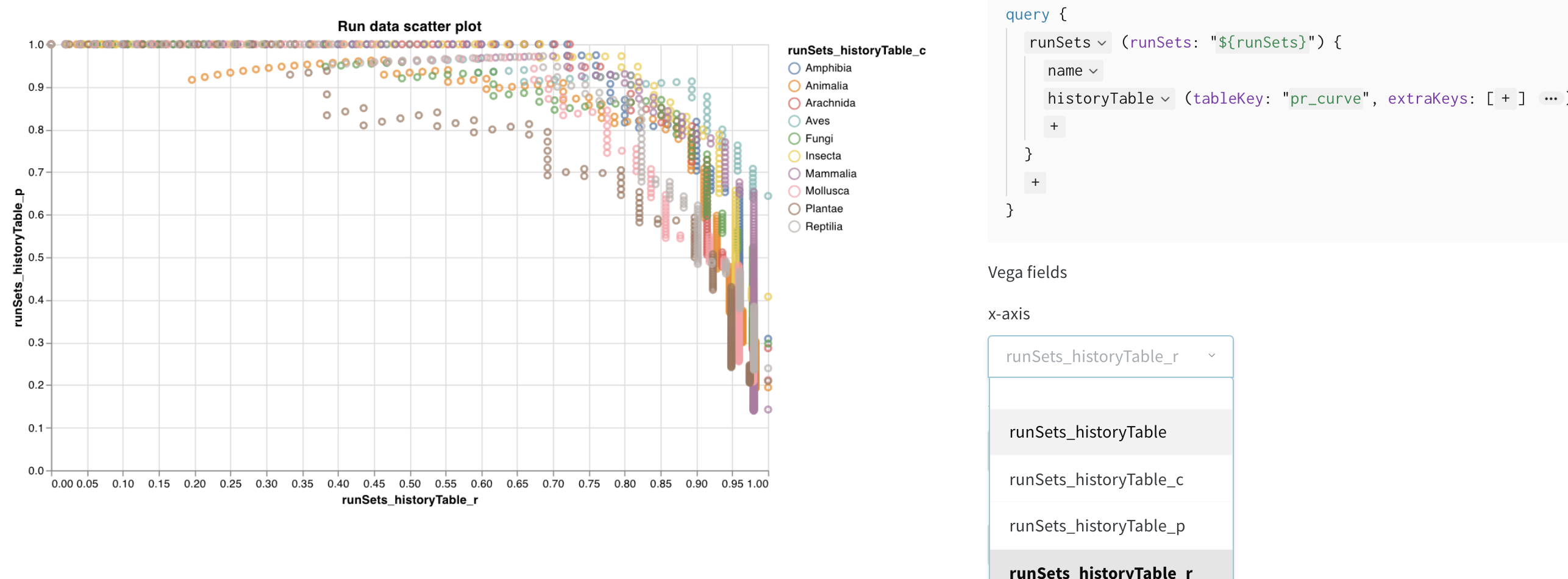
- x-axis: runSets_historyTable_r (recall)
- y-axis: runSets_historyTable_p (precision)
- color: runSets_historyTable_c (class label)
3. 차트 커스터마이징
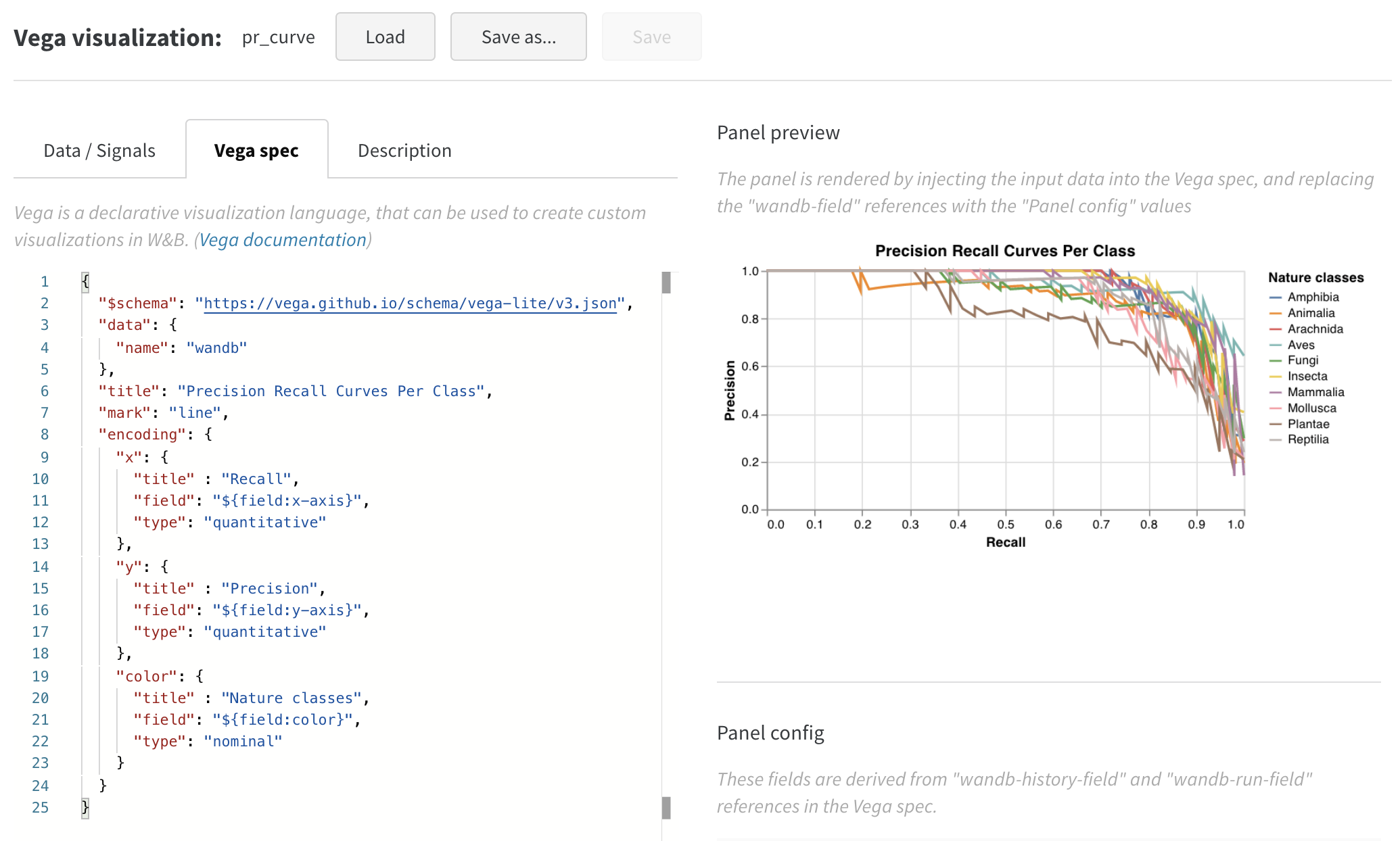
차트가 꽤 괜찮아 보이지만, 산점도(scatter plot) 대신 선 그래프(line plot)로 바꾸고 싶습니다. Edit을 클릭하여 이 내장 차트의 Vega 스펙을 변경하세요. 커스텀 차트 데모 워크스페이스에서 함께 진행할 수 있습니다.
- 플롯, 범례, x축, y축의 제목 추가 (각 필드에 “title” 설정)
- “mark” 값을 “point”에서 “line”으로 변경
- 사용하지 않는 “size” 필드 제거
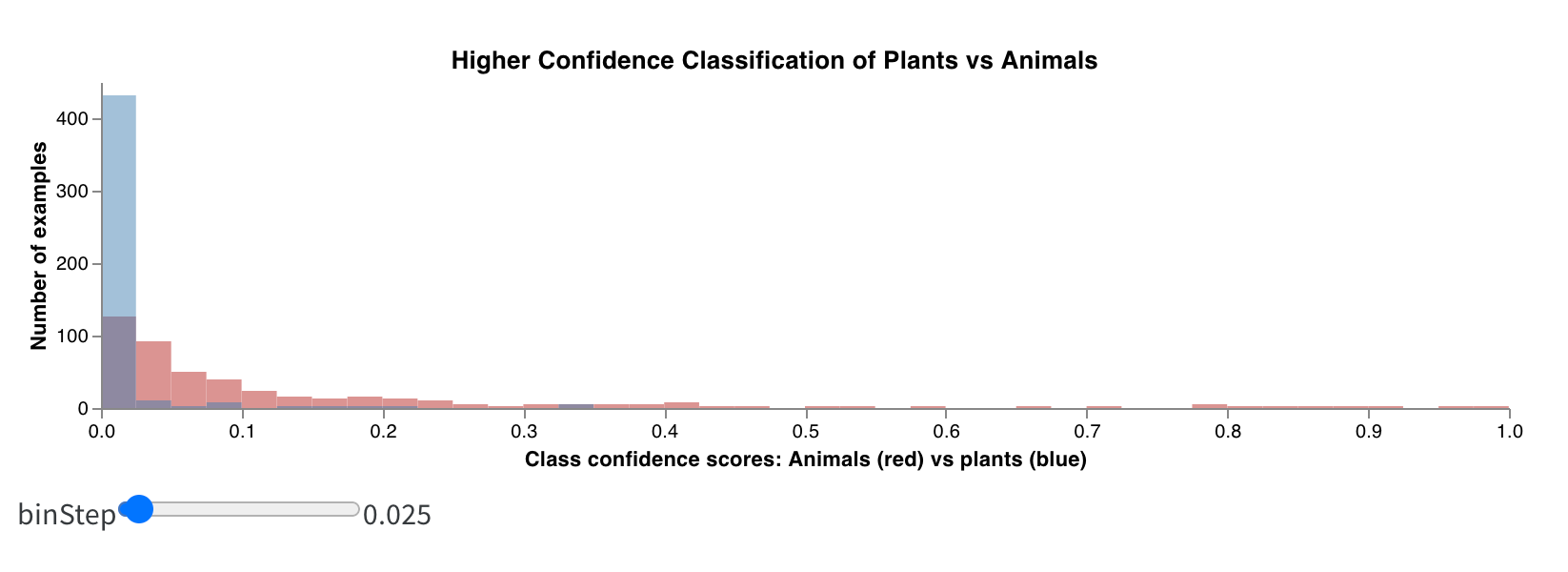
보너스: 복합 히스토그램 (Composite Histograms)
히스토그램은 수치 분포를 시각화하여 대규모 데이터셋을 이해하는 데 도움을 줍니다. 복합 히스토그램은 동일한 빈(bin)에 여러 분포를 표시하여, 서로 다른 모델 간 또는 모델 내의 서로 다른 클래스 간에 두 개 이상의 메트릭을 비교할 수 있게 해줍니다. 예를 들어 주행 장면의 오브젝트를 감지하는 시멘틱 세그멘테이션 모델의 경우, 정확도(accuracy) 최적화와 IOU (intersection over union) 최적화의 효과를 비교하거나, 서로 다른 모델이 자동차(크고 흔한 영역)와 교통 표지판(훨씬 작고 덜 흔한 영역)을 얼마나 잘 감지하는지 알고 싶을 수 있습니다. 데모 Colab에서는 10가지 생물 클래스 중 두 클래스에 대한 신뢰도 점수(confidence scores)를 비교해 볼 수 있습니다.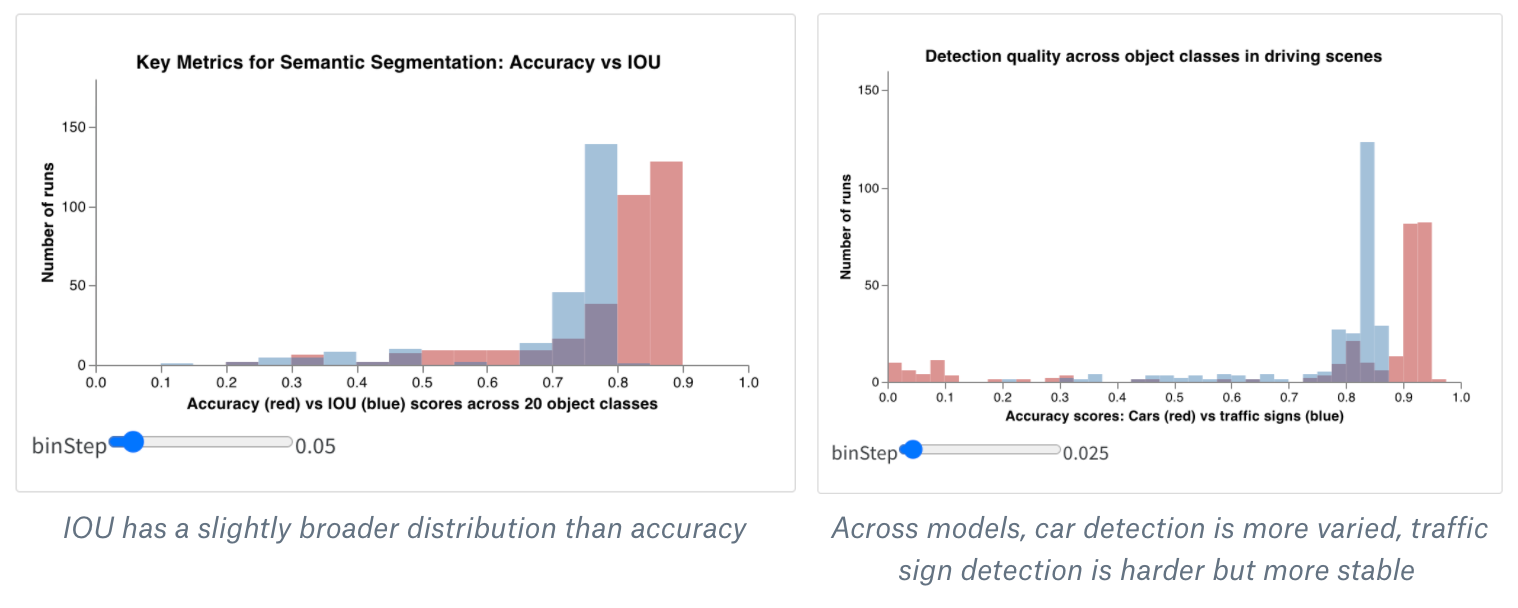
- Workspace 또는 Report에서 새 Custom Chart 패널을 생성합니다 (“Custom Chart” 시각화 추가). 우측 상단의 “Edit” 버튼을 눌러 내장 패널 유형 중 하나를 시작점으로 Vega 스펙을 수정합니다.
- 해당 내장 Vega 스펙을 저의 복합 히스토그램을 위한 MVP Vega 코드로 교체합니다. Vega 문법을 사용하여 이 Vega 스펙 내에서 메인 제목, 축 제목, 입력 도메인 및 기타 세부 사항을 직접 수정할 수 있습니다 (색상을 바꾸거나 세 번째 히스토그램을 추가할 수도 있습니다 :)
- 우측의 쿼리를 수정하여 wandb 로그에서 올바른 데이터를 로드합니다.
summaryTable필드를 추가하고 해당tableKey를class_scores로 설정하여 run에 의해 로그된wandb.Table을 가져옵니다. 이를 통해 드롭다운 메뉴에서class_scores로 로그된wandb.Table의 컬럼들을 선택하여 두 개의 히스토그램 빈 세트(red_bins및blue_bins)를 채울 수 있습니다. 저의 예제에서는 빨간색 빈에는animal클래스 예측 점수를, 파란색 빈에는plant를 선택했습니다. - 미리보기 렌더링에 나타나는 플롯이 마음에 들 때까지 Vega 스펙과 쿼리를 계속 수정할 수 있습니다. 작업이 끝나면 상단의 Save as를 클릭하고 커스텀 플롯의 이름을 지정하여 재사용할 수 있게 합니다. 그런 다음 Apply from panel library를 클릭하여 플롯을 완성합니다.