- 모델, 에포크 또는 개별 예제 간의 변화를 정밀하게 비교
- 데이터의 상위 수준 패턴 이해
- 시각적 샘플을 통해 인사이트를 포착하고 공유
W&B Tables는 다음과 같은 동작을 가집니다:
- Artifacts 컨텍스트에서의 Stateless: Artifact 버전과 함께 로그된 모든 테이블은 브라우저 창을 닫으면 기본 상태로 리셋됩니다.
- Workspace 또는 Reports 컨텍스트에서의 Stateful: 단일 run Workspace, 멀티 run 프로젝트 Workspace 또는 Reports에서 테이블에 가한 모든 변경 사항은 유지됩니다.
두 테이블 비교하기
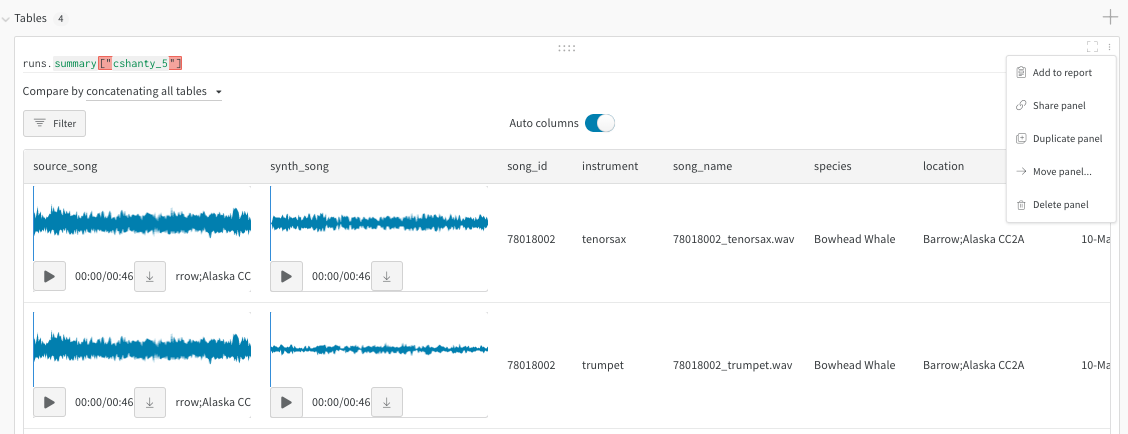
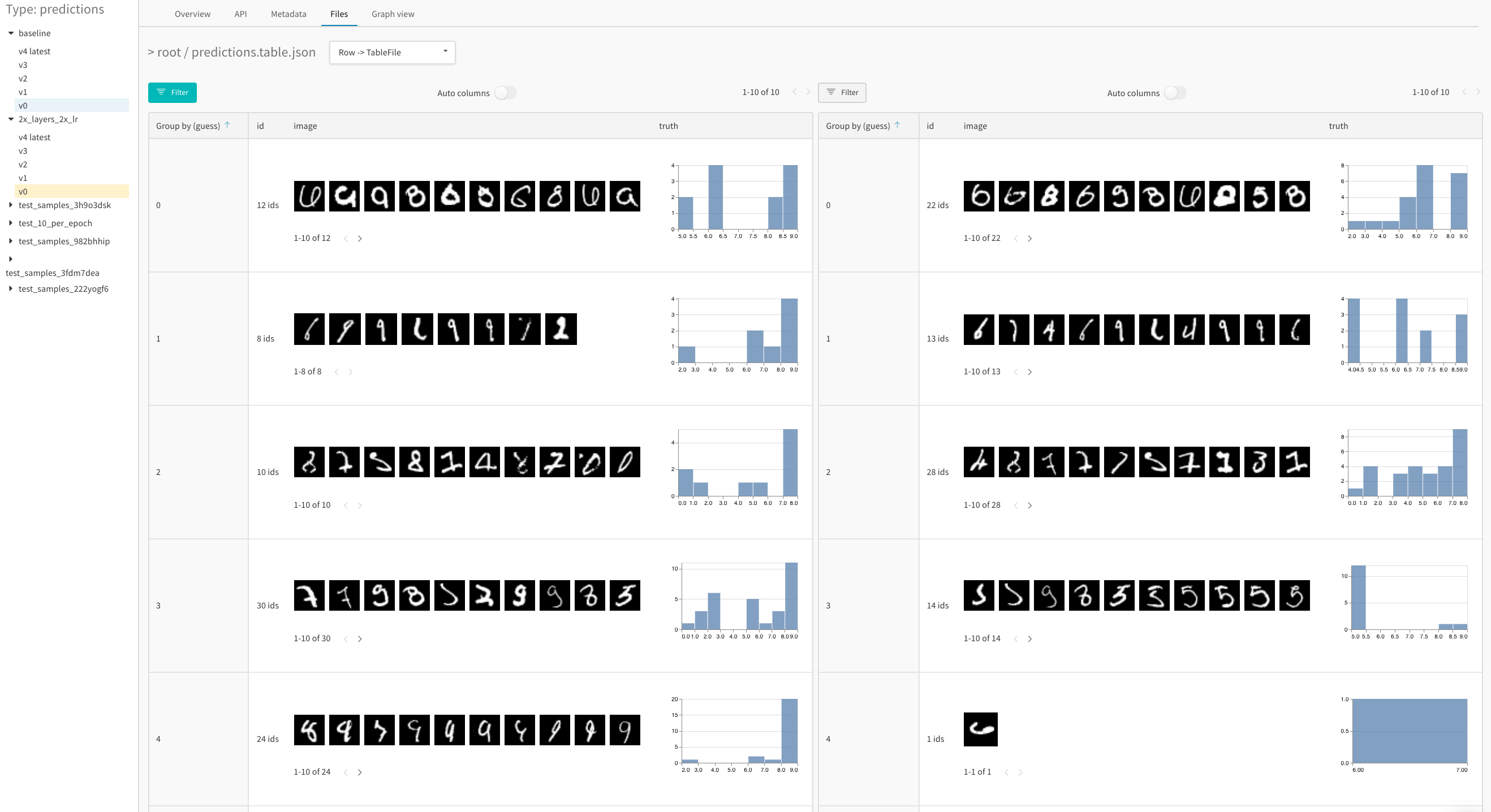
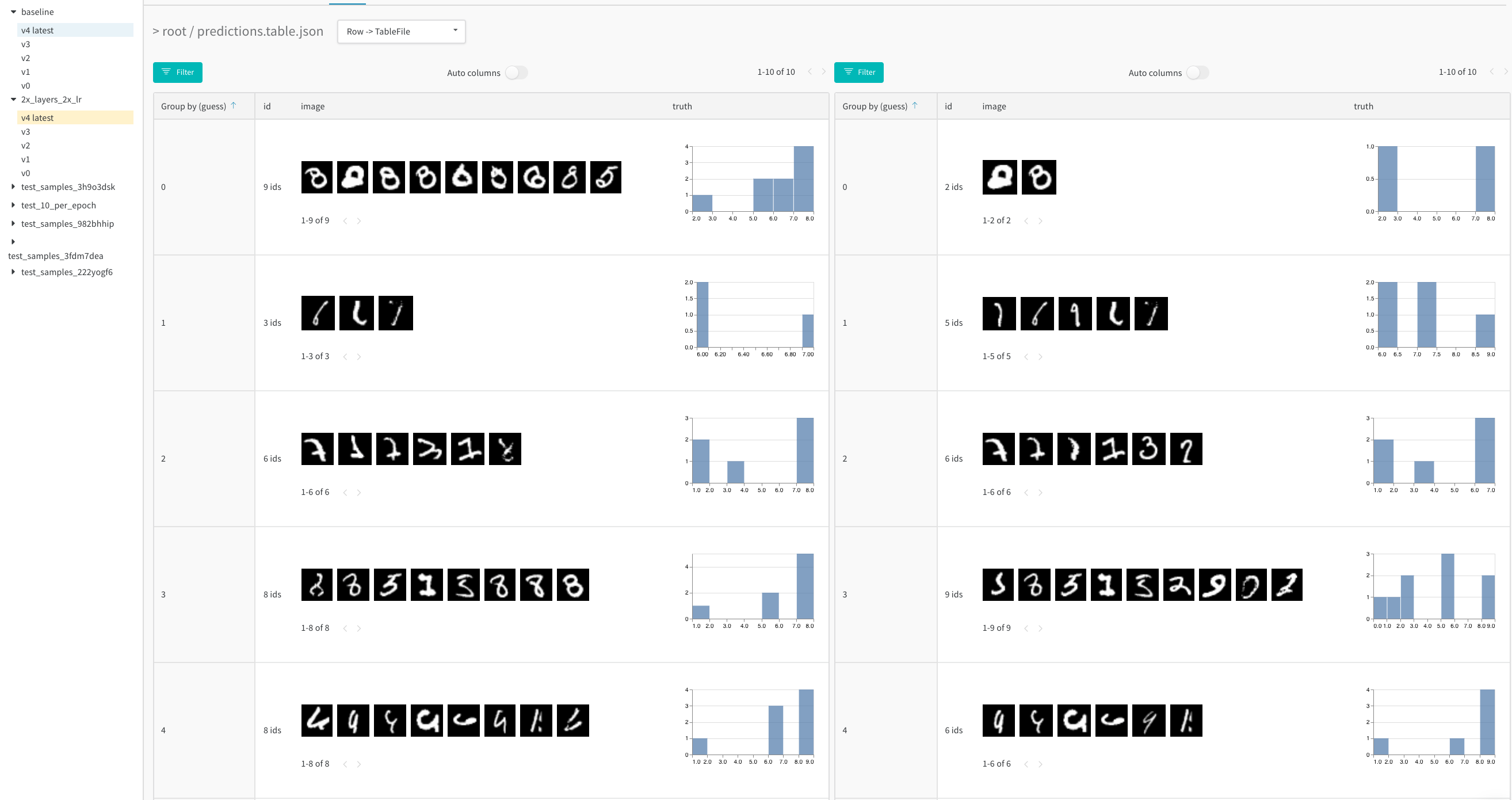
병합 뷰 (merged view) 또는 나란히 보기 뷰 (side-by-side view)를 사용하여 두 테이블을 비교하세요. 예를 들어, 아래 이미지는 MNIST 데이터의 테이블 비교를 보여줍니다.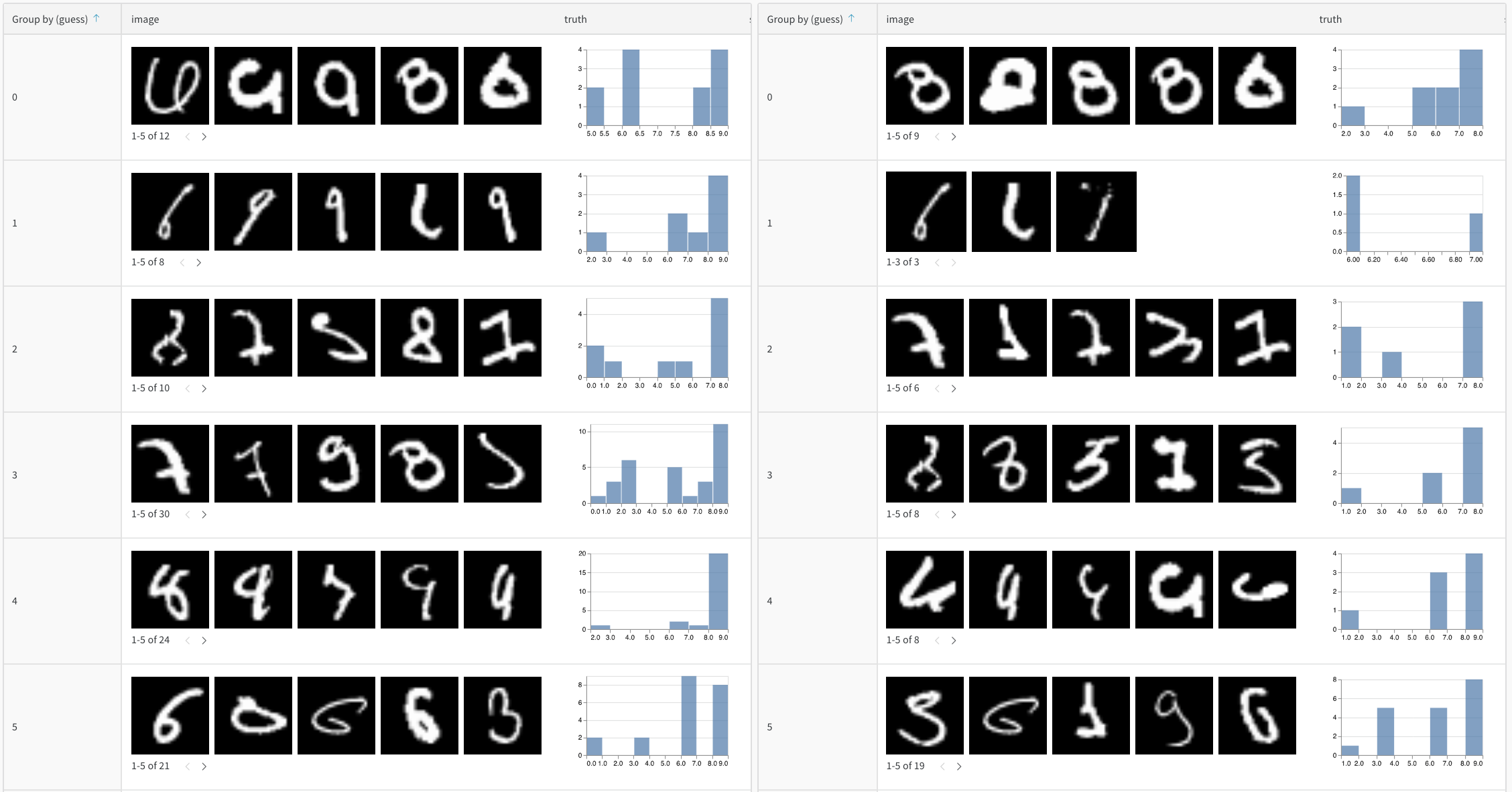
- W&B 앱의 프로젝트로 이동합니다.
- 왼쪽 패널에서 Artifacts 아이콘을 선택합니다.
- Artifact 버전을 선택합니다.
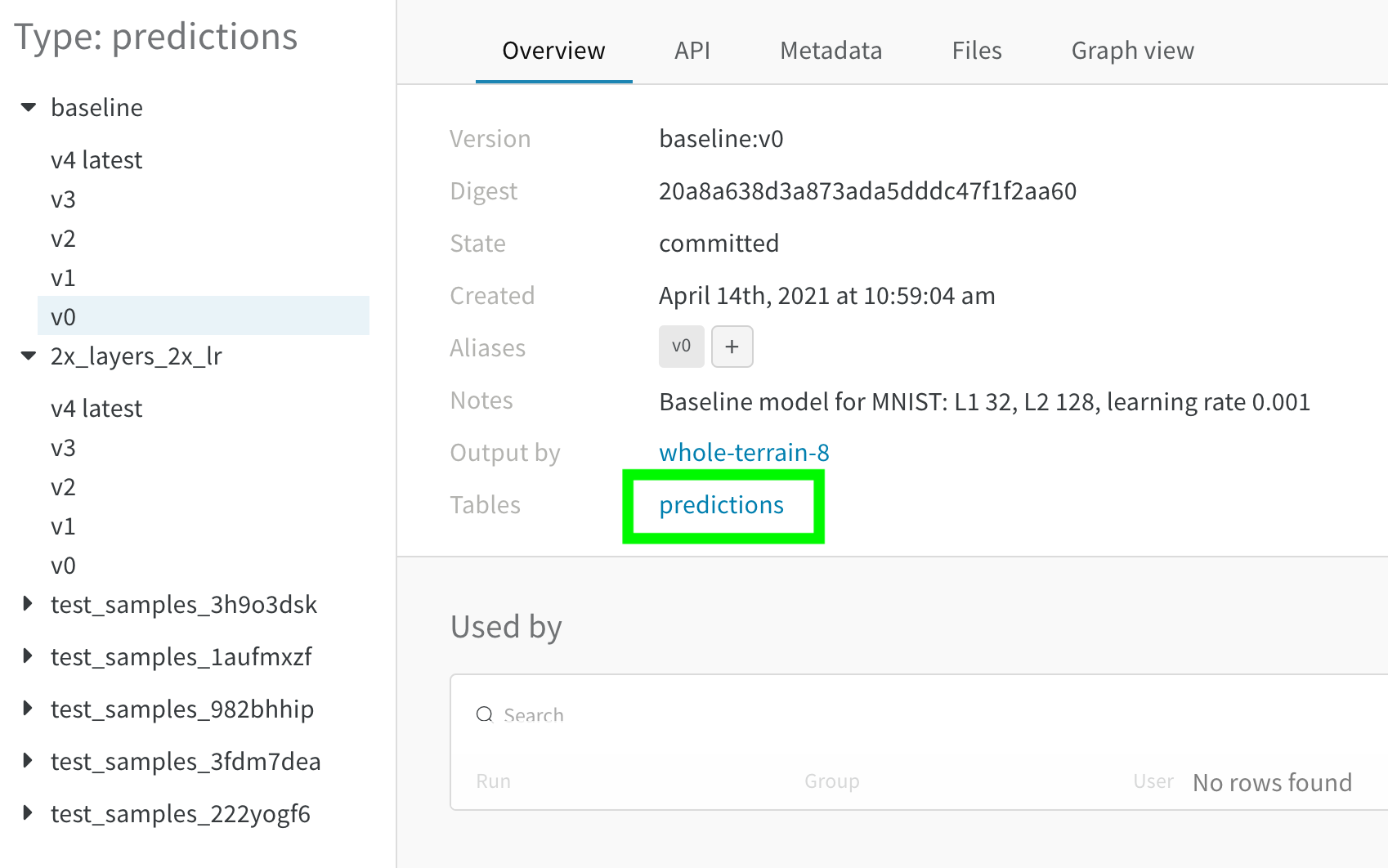
- 사이드바에서 비교하려는 두 번째 Artifact 버전에 마우스를 올리고 Compare가 나타나면 클릭합니다. 예를 들어, 아래 이미지에서는 5 에포크 트레이닝 후 동일한 모델이 만든 MNIST 예측값과 비교하기 위해 “v4”로 라벨링된 버전을 선택합니다.
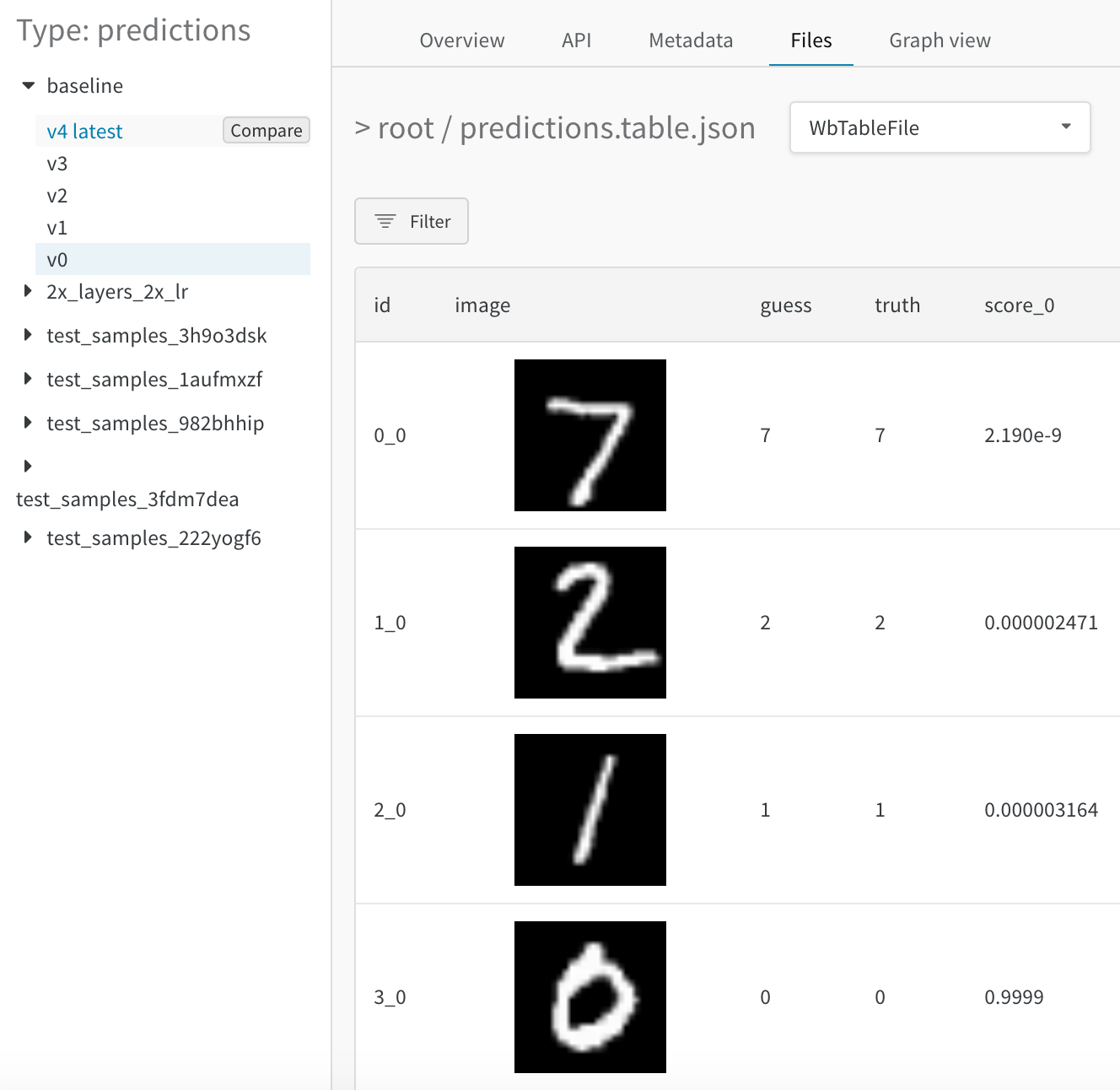
병합 뷰 (Merged view)
처음에는 두 테이블이 함께 병합된 상태로 표시됩니다. 첫 번째로 선택된 테이블은 인덱스 0과 파란색 하이라이트를 가지며, 두 번째 테이블은 인덱스 1과 노란색 하이라이트를 가집니다. 병합된 테이블의 라이브 예제를 여기에서 확인하세요.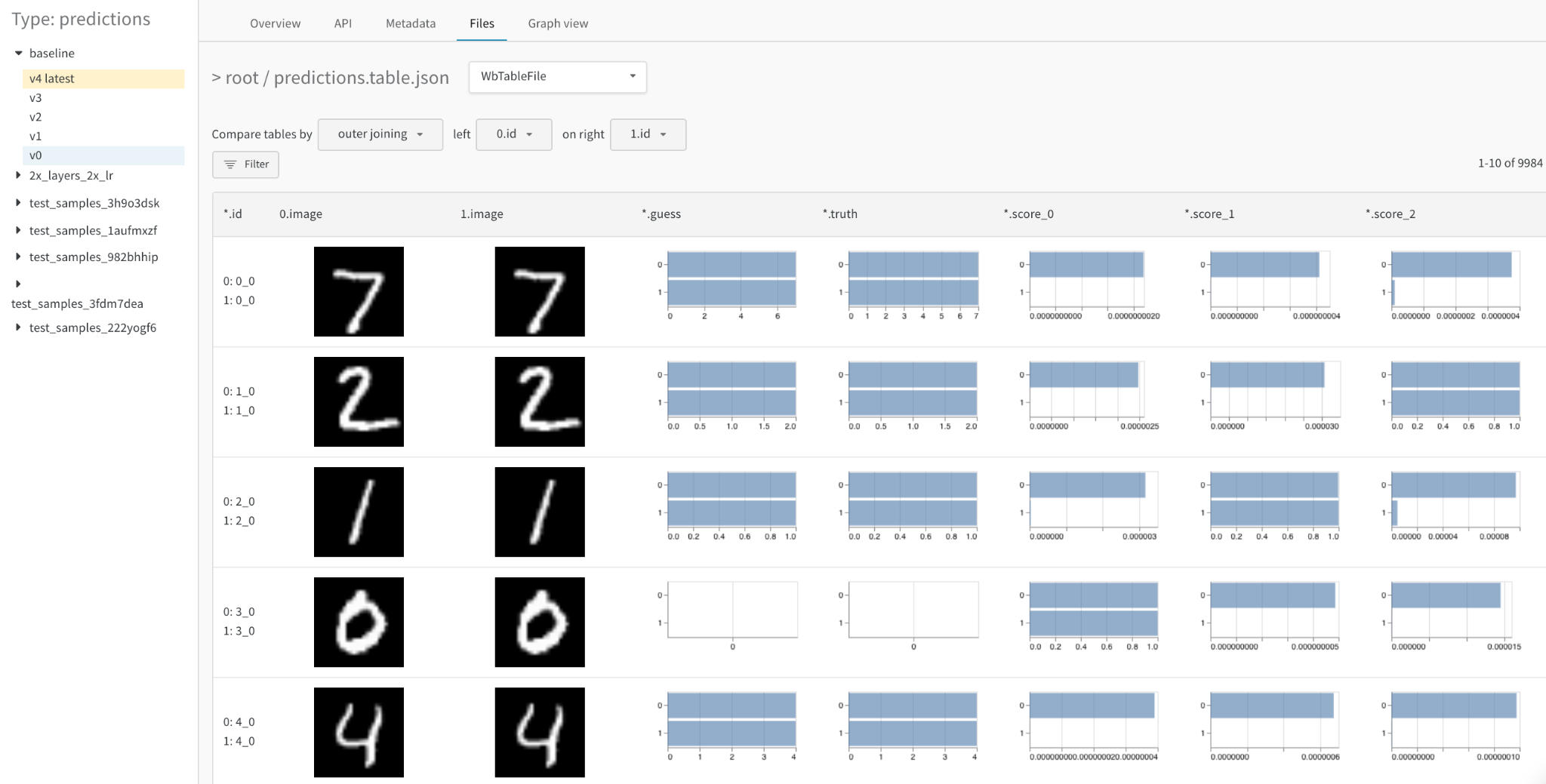
- 조인 키(join key) 선택: 왼쪽 상단의 드롭다운을 사용하여 두 테이블의 조인 키로 사용할 컬럼을 설정합니다. 일반적으로 데이터셋의 각 예제에 대한 고유 식별자(예: 파일 이름)나 생성된 샘플의 증가하는 인덱스입니다. 현재는 모든 컬럼을 선택할 수 있지만, 부적절한 컬럼을 선택하면 테이블을 읽기 어려워지거나 쿼리 속도가 느려질 수 있습니다.
- 조인 대신 연결(concatenate): 이 드롭다운에서 “concatenating all tables”를 선택하면 컬럼을 가로로 합치는 대신 두 테이블의 모든 행을 하나로 합쳐 더 큰 테이블을 만듭니다.
- 각 테이블 명시적 참조: 필터 표현식에서 0, 1, *을 사용하여 하나 또는 두 테이블 인스턴스의 컬럼을 명시적으로 지정합니다.
- 수치적 차이를 히스토그램으로 시각화: 모든 셀의 값을 한눈에 비교할 수 있습니다.
나란히 보기 뷰 (Side-by-side view)
두 테이블을 나란히 보려면 첫 번째 드롭다운을 “Merge Tables: Table”에서 “List of: Table”로 변경한 다음 “Page size”를 적절히 업데이트하세요. 여기서 첫 번째로 선택한 테이블은 왼쪽에, 두 번째 테이블은 오른쪽에 표시됩니다. 또한 “Vertical” 체크박스를 클릭하여 이 테이블들을 세로로 비교할 수도 있습니다.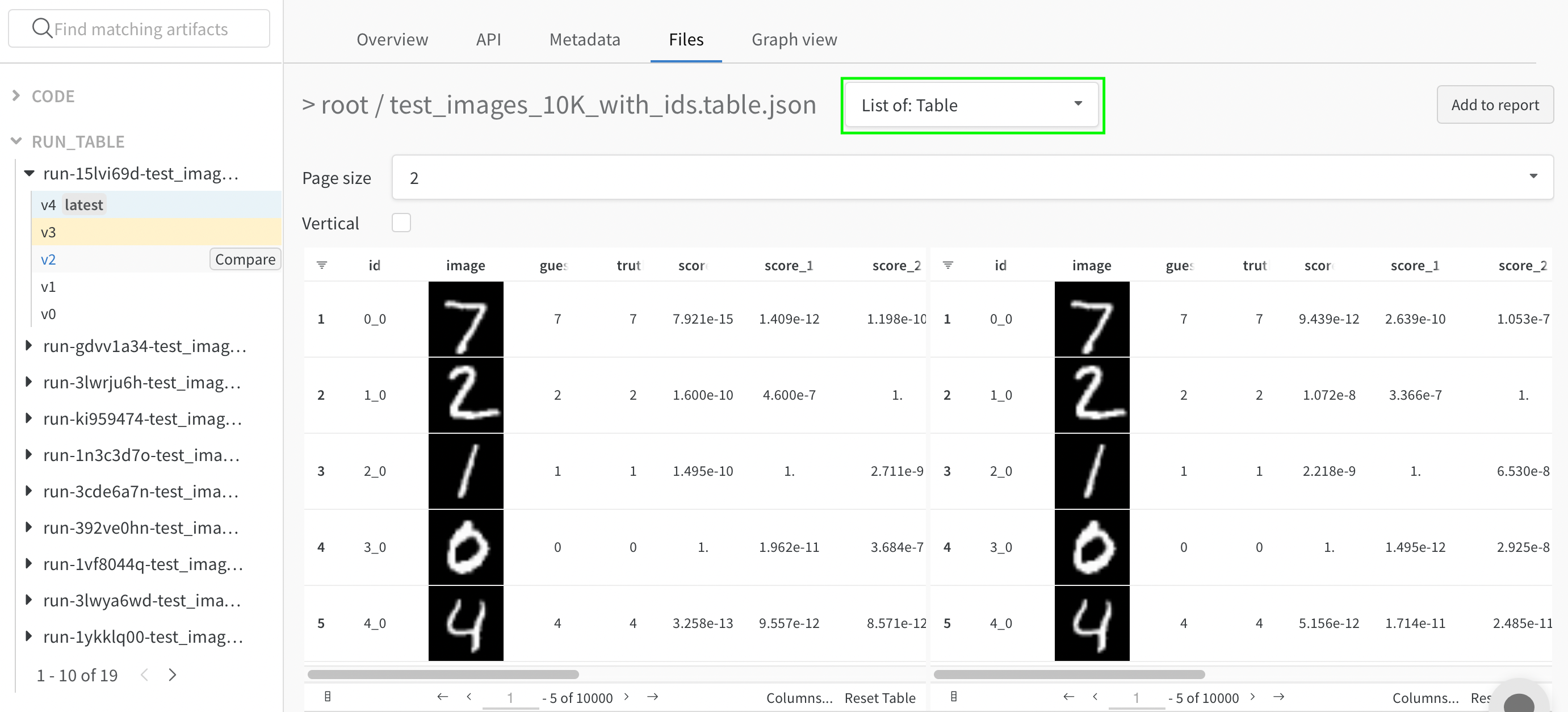
- 한눈에 테이블 비교: 정렬, 필터, 그룹화 등의 작업을 두 테이블에 동시에 적용하여 변화나 차이점을 빠르게 포착하세요. 예를 들어, 추측값별로 그룹화된 잘못된 예측값, 전체적으로 가장 오답률이 높은 네거티브 샘플, 실제 라벨별 신뢰도 점수 분포 등을 확인할 수 있습니다.
- 독립적으로 두 테이블 탐색: 스크롤을 통해 관심 있는 측면이나 행에 집중하세요.
Runs 전반에 걸친 값의 변화 시각화하기
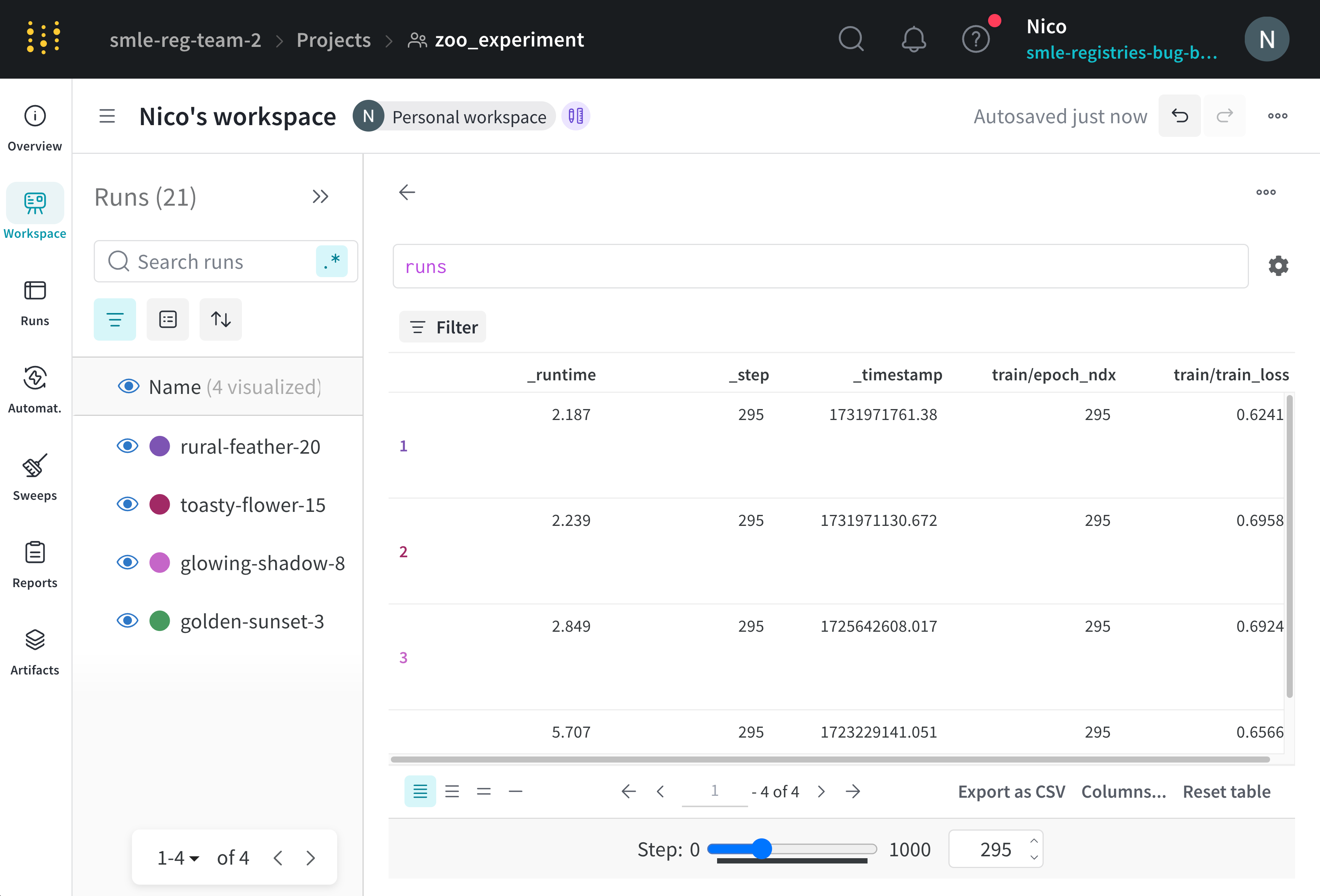
스텝 슬라이더를 사용하여 테이블에 기록한 값이 Runs 전반에 걸쳐 어떻게 변하는지 확인하세요. 스텝 슬라이더를 밀어서 서로 다른 스텝에 로그된 값을 볼 수 있습니다. 예를 들어, 각 run 이후에 loss, accuracy 또는 기타 메트릭이 어떻게 변하는지 확인할 수 있습니다. 슬라이더는 키를 사용하여 스텝 값을 결정합니다. 슬라이더의 기본 키는_step으로, W&B가 자동으로 로그하는 특수 키입니다. _step 키는 코드에서 wandb.Run.log()를 호출할 때마다 1씩 증가하는 정수입니다.
W&B Table에 스텝 슬라이더를 추가하려면:
- 프로젝트의 Workspace로 이동합니다.
- Workspace 오른쪽 상단 모서리에 있는 Add panel을 클릭합니다.
- Query panel을 선택합니다.
- 쿼리 표현식 에디터 내에서
runs를 선택하고 키보드의 Enter를 누릅니다. - 기어 아이콘을 클릭하여 패널 설정을 확인합니다.
- Render As 선택기를 Stepper로 설정합니다.
- Stepper Key를
_step또는 스텝 슬라이더의 단위로 사용할 키로 설정합니다.
커스텀 스텝 키 (Custom step key)
스텝 키는epoch나 global_step과 같이 Runs에서 로그하는 모든 숫자형 메트릭이 될 수 있습니다. 커스텀 스텝 키를 사용하면 W&B는 해당 키의 각 값을 run의 스텝(_step)에 매핑합니다.
이 테이블은 커스텀 스텝 키 epoch가 세 개의 서로 다른 Runs(serene-sponge, lively-frog, vague-cloud)에 대해 _step 값에 어떻게 매핑되는지 보여줍니다. 각 행은 run의 특정 _step에서 호출된 wandb.Run.log()를 나타냅니다. 컬럼은 해당 스텝에서 로그된 에포크 값을 보여줍니다. 공간 절약을 위해 일부 _step 값은 생략되었습니다.
wandb.Run.log()가 처음 호출되었을 때, 어떤 Runs도 epoch 값을 로그하지 않았으므로 테이블에는 epoch 값이 비어 있습니다.
_step | vague-cloud (epoch) | lively-frog(epoch) | serene-sponge (epoch) |
|---|---|---|---|
| 1 | |||
| 2 | 1 | ||
| 4 | 1 | 2 | |
| 5 | 1 | ||
| 6 | 3 | ||
| 8 | 2 | 4 | |
| 10 | 5 | ||
| 12 | 3 | 6 | |
| 14 | 7 | ||
| 15 | 2 | ||
| 16 | 4 | 8 | |
| 18 | 9 | ||
| 20 | 3 | 5 | 10 |
epoch = 1로 설정되면 다음과 같은 일이 발생합니다:
vague-cloud는epoch = 1을 찾고_step = 5에서 로그된 값을 반환합니다.lively-frog는epoch = 1을 찾고_step = 4에서 로그된 값을 반환합니다.serene-sponge는epoch = 1을 찾고_step = 2에서 로그된 값을 반환합니다.
epoch = 9로 설정되면:
vague-cloud역시epoch = 9를 로그하지 않았으므로, W&B는 이전의 마지막 값인epoch = 3을 사용하고_step = 20에서 로그된 값을 반환합니다.lively-frog는epoch = 9를 로그하지 않았지만, 이전의 마지막 값이epoch = 5이므로_step = 20에서 로그된 값을 반환합니다.serene-sponge는epoch = 9를 찾고_step = 18에서 로그된 값을 반환합니다.
Artifacts 비교하기
시간에 따른 테이블 비교 또는 모델 변체 간 비교를 수행할 수도 있습니다.시간에 따른 테이블 비교
트레이닝의 각 유의미한 스텝마다 Artifact에 테이블을 로그하여 시간에 따른 모델 성능을 분석하세요. 예를 들어, 매 검증 스텝이 끝날 때마다, 트레이닝 50 에포크마다, 또는 파이프라인에 적합한 빈도로 테이블을 로그할 수 있습니다. 나란히 보기 뷰를 사용하여 모델 예측값의 변화를 시각화하세요.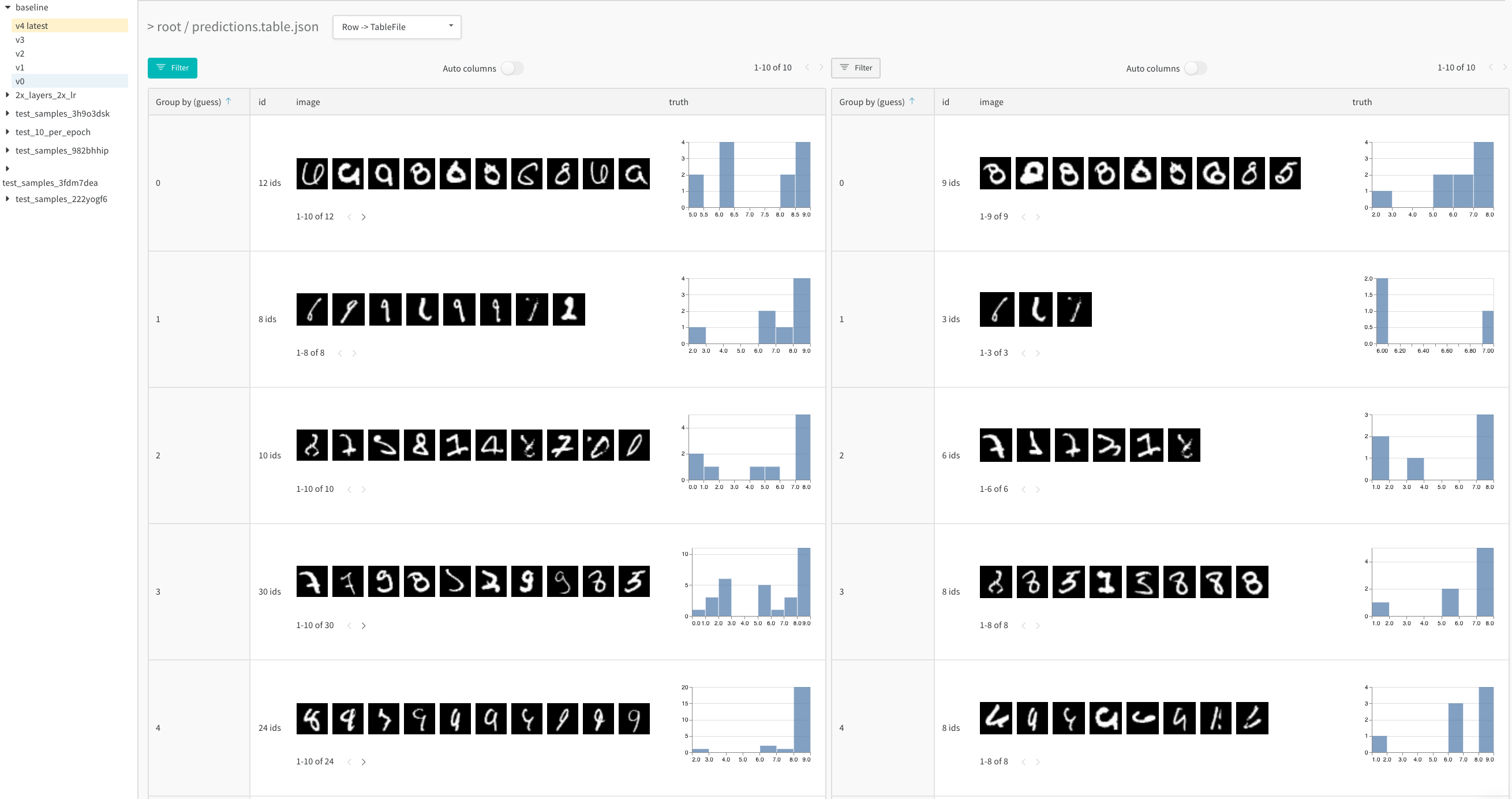
모델 변체 간 테이블 비교
서로 다른 두 모델에 대해 동일한 스텝에서 로그된 두 Artifact 버전을 비교하여 다양한 설정(하이퍼파라미터, 베이스 아키텍처 등)에 따른 모델 성능을 분석하세요. 예를 들어,baseline 모델과 새로운 모델 변체인 2x_layers_2x_lr(첫 번째 컨볼루션 레이어가 32에서 64로, 두 번째는 128에서 256으로, 학습률은 0.001에서 0.002로 두 배 증가) 간의 예측값을 비교해 보세요. 이 라이브 예제에서 나란히 보기 뷰를 사용하고, 1 에포크(왼쪽 탭)와 5 에포크 트레이닝 후(오른쪽 탭)의 잘못된 예측값만 필터링하여 확인해 보세요.
- 1 training epoch
- 5 training epochs
뷰 저장하기
Run Workspace, 프로젝트 Workspace 또는 Reports에서 상호작용하는 테이블은 뷰 상태를 자동으로 저장합니다. 테이블 작업을 적용한 후 브라우저를 닫더라도, 다음에 테이블로 이동할 때 마지막으로 확인한 설정이 유지됩니다.Artifacts 컨텍스트에서 상호작용하는 테이블은 상태가 유지되지 않습니다(stateless).
- Workspace 시각화 패널의 오른쪽 상단 모서리에 있는 케밥 아이콘(세 개의 수직 점)을 선택합니다.
- Share panel 또는 Add to report를 선택합니다.