1. W&B へのデータのログ記録
まず、スクリプトでデータをログに記録します。ハイパーパラメーターのように、トレーニングの開始時に設定される単一のポイントには wandb.Run.config を使用してください。時系列に沿った複数のポイントには wandb.Run.log() を使用し、カスタムの 2D 配列はwandb.Table() でログを記録します。ログを記録する キー (key) ごとに、最大 10,000 データポイントまでのログ記録を推奨しています。
2. クエリの作成
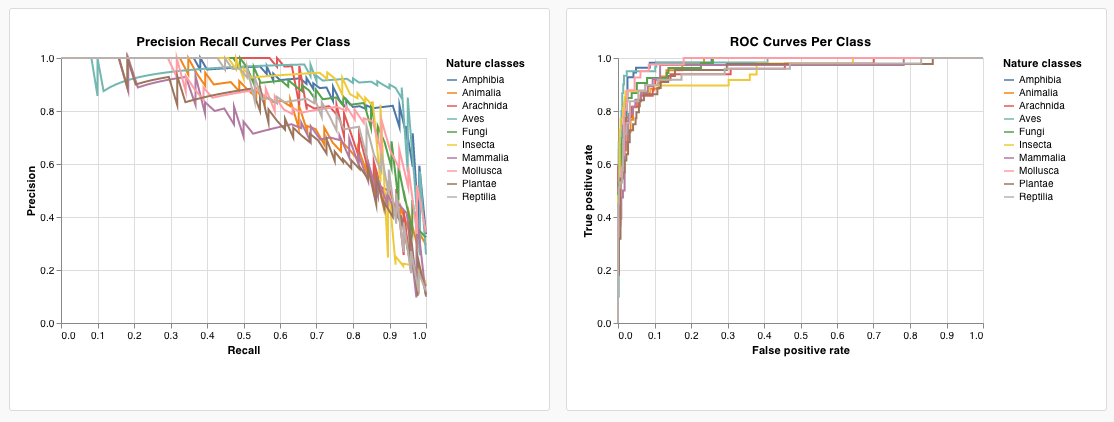
可視化するデータのログを記録したら、Projects ページに移動し、+ ボタンをクリックして新しい パネル を追加し、Custom Chart を選択します。カスタムチャート デモ Workspace で手順を確認しながら進めることができます。

クエリの追加
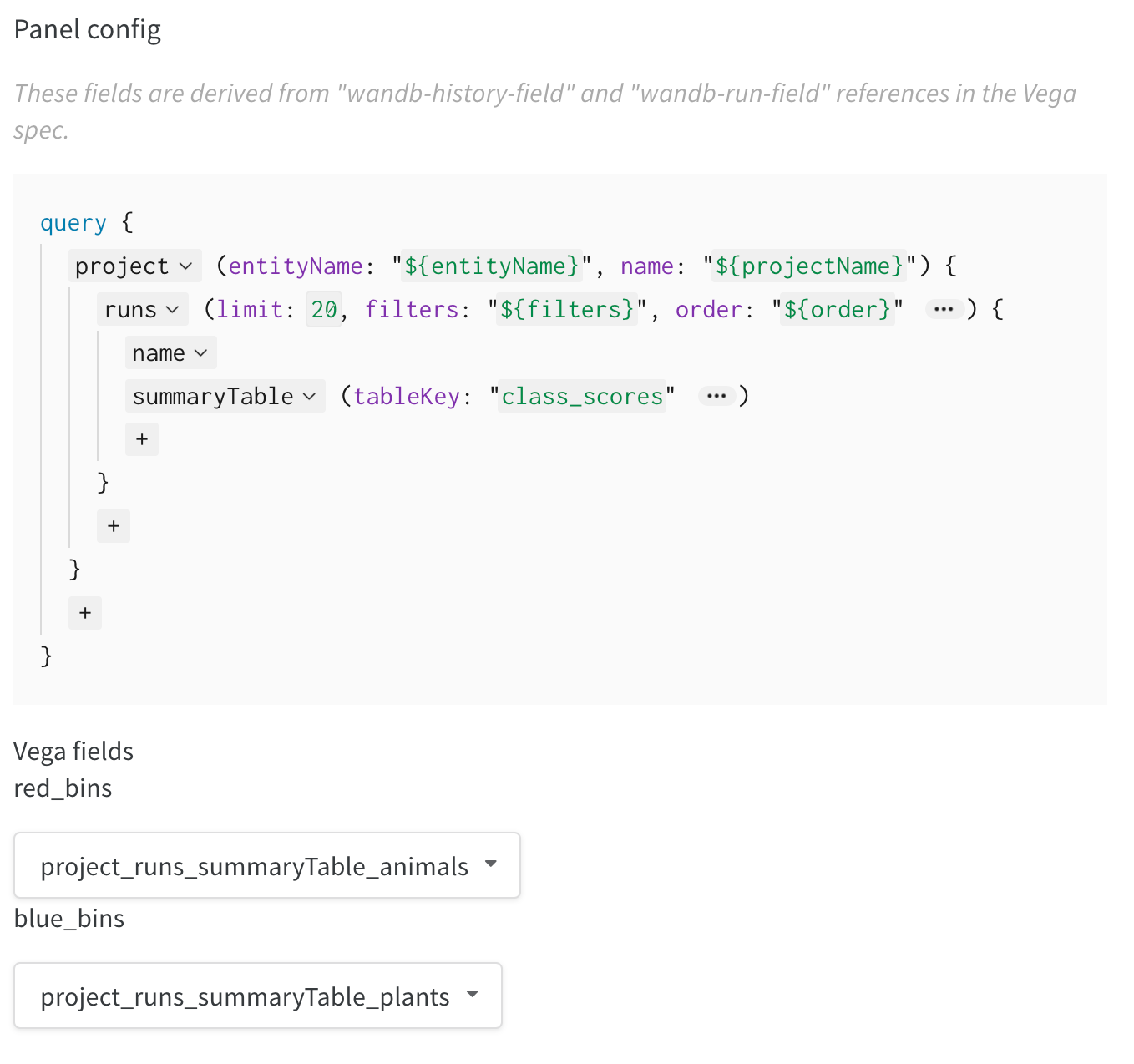
summaryをクリックしてhistoryTableを選択し、Run の履歴からデータを取得する新しいクエリを設定します。wandb.Table()をログに記録した際の キー (key) を入力します。上記のコードスニペットではmy_custom_tableでした。サンプルノートブック では、キーはpr_curveとroc_curveです。
Vega フィールドの設定
クエリがこれらの列を読み込むようになると、Vega フィールドのドロップダウンメニューから選択可能なオプションとして表示されます。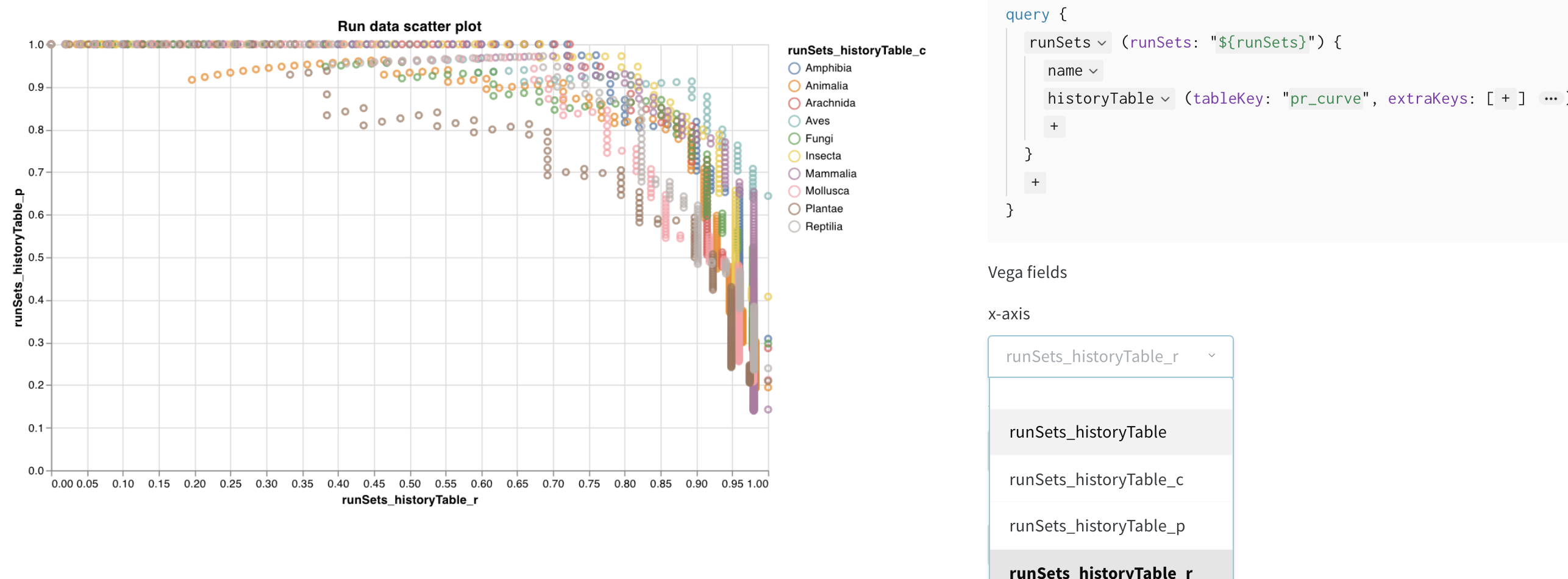
- x-axis: runSets_historyTable_r (再現率 / recall)
- y-axis: runSets_historyTable_p (適合率 / precision)
- color: runSets_historyTable_c (クラスラベル)
3. チャートのカスタマイズ
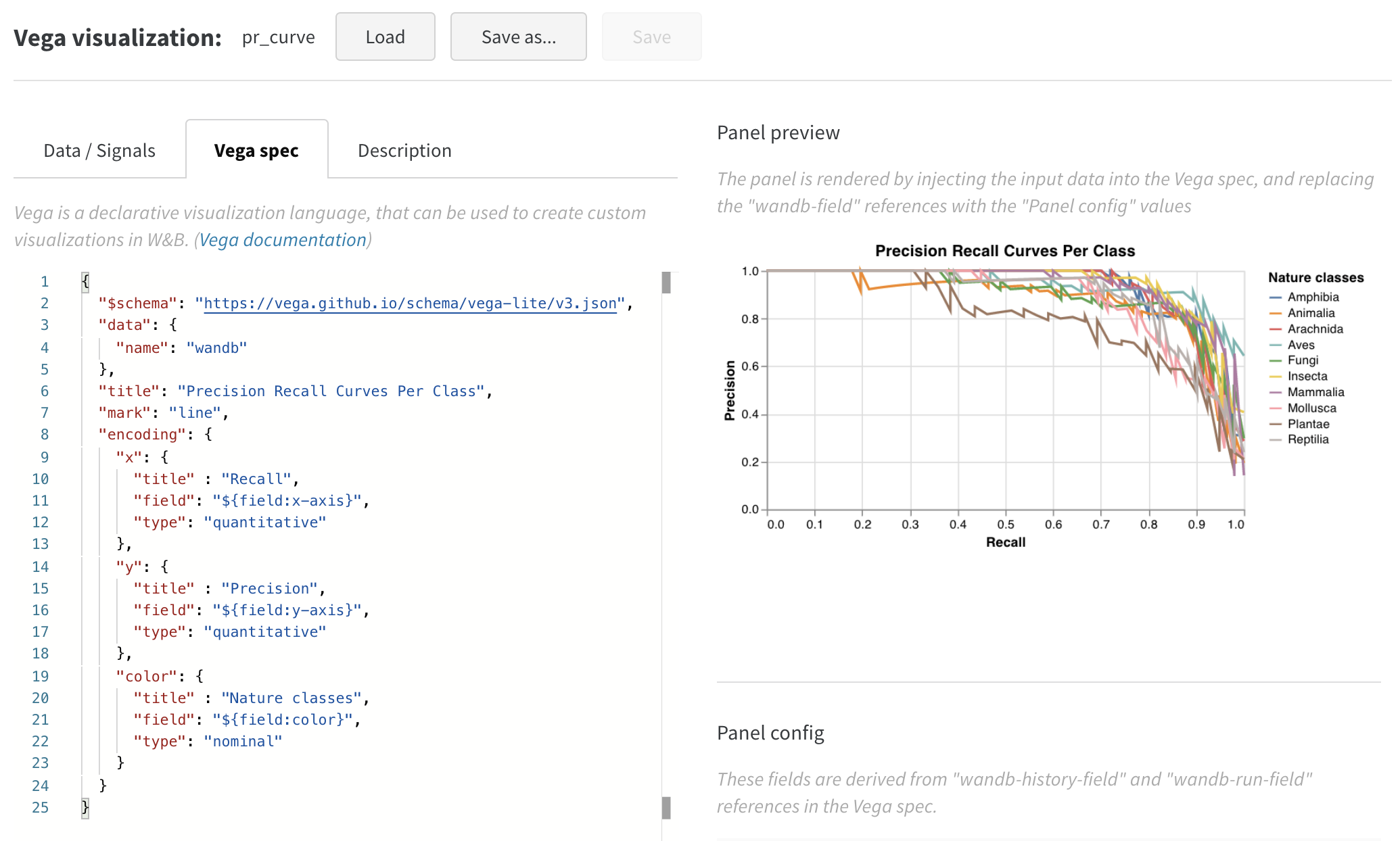
これでかなり良くなりましたが、散布図から折れ線グラフに切り替えたいと思います。Edit をクリックして、この組み込みチャートの Vega spec を変更します。カスタムチャート デモ Workspace で一緒に進めてみましょう。
- プロット、凡例、x 軸、y 軸のタイトルを追加(各フィールドに “title” を設定)
- “mark” の値を “point” から “line” に変更
- 未使用の “size” フィールドを削除
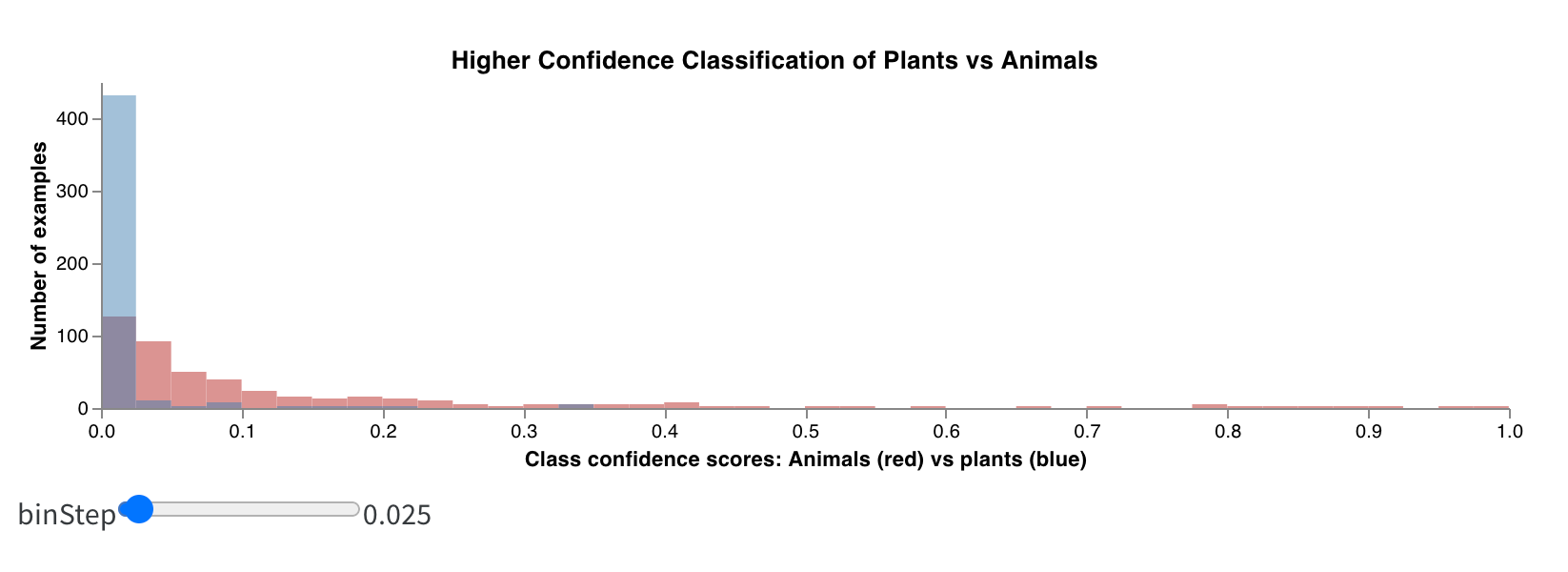
ボーナス: 複合ヒストグラム (Composite Histograms)
ヒストグラムは、数値の分布を可視化して、より大規模な データセット を理解するのに役立ちます。複合ヒストグラムは、同じビンを介して複数の分布を表示し、異なる モデル 間やモデル内の異なるクラス間で 2 つ以上の メトリクス を比較することを可能にします。走行シーンの物体を検出する セマンティックセグメンテーション モデルの場合、精度 (accuracy) の最適化と Intersection over union (IoU) の最適化の効果を比較したり、モデルが車(データ内で大きく一般的な領域)と交通標識(はるかに小さく、あまり一般的でない領域)をどの程度うまく検出できるかを知りたい場合があります。デモ Colab では、10 種類の生物クラスのうち 2 つの信頼度スコアを比較できます。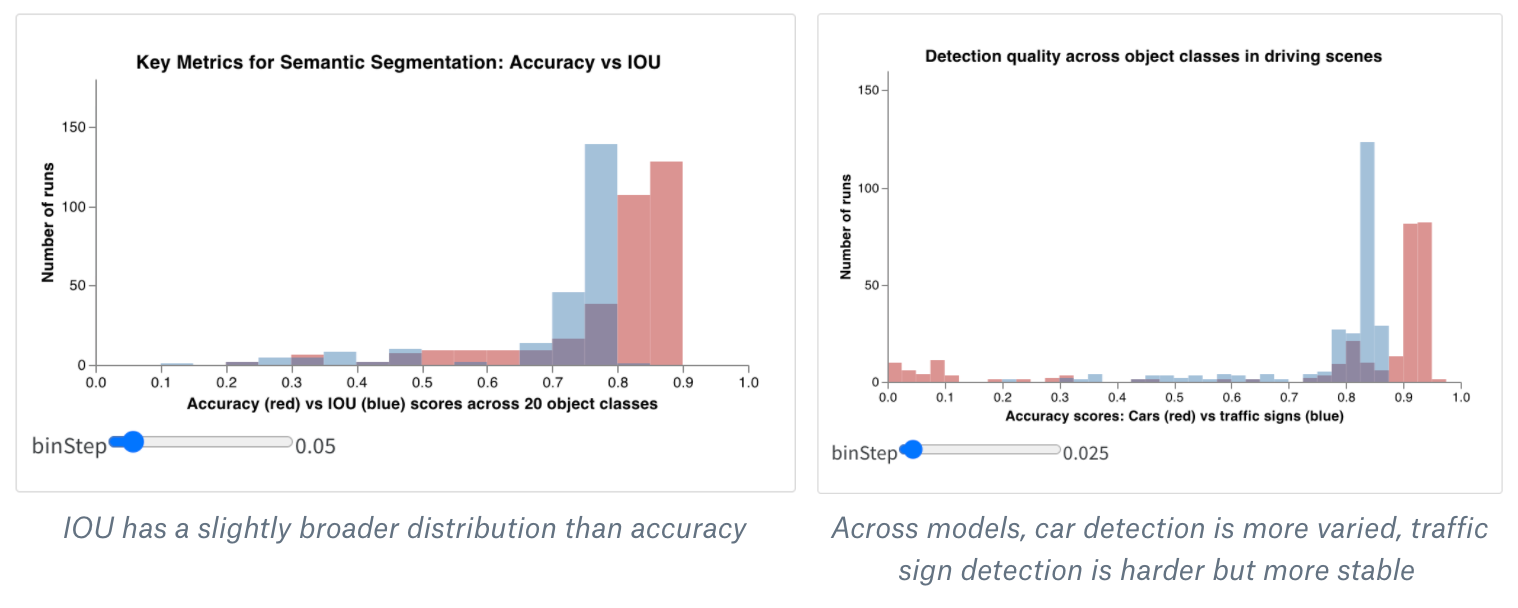
- Workspace または Reports 内で新しい Custom Chart パネルを作成します(「Custom Chart」可視化を追加)。右上の「Edit」ボタンを押して、任意の組み込みパネルタイプから Vega spec を変更します。
- その組み込み Vega spec を、こちらの Vega での複合ヒストグラム用 MVP コード に置き換えます。メインタイトル、軸タイトル、入力ドメイン、その他の詳細は、Vega の構文を使用して この Vega spec 内で直接変更できます(色を変えたり、3 つ目のヒストグラムを追加することも可能です)。
- 右側のクエリを修正して、W&B のログから正しいデータを読み込むようにします。
summaryTableフィールドを追加し、対応するtableKeyをclass_scoresに設定して、Run によってログに記録されたwandb.Tableを取得します。これにより、ドロップダウンメニューを使用して、class_scoresとしてログに記録されたwandb.Tableの列から、2 つのヒストグラムのビンセット(red_binsとblue_bins)にデータを入力できるようになります。私の例では、赤のビンにanimalクラスの予測スコアを、青のビンにplantクラスの予測スコアを選択しました。 - プレビューに表示されるプロットに満足するまで、Vega spec とクエリの変更を続けることができます。完了したら、上部の Save as をクリックしてカスタムプロットに名前を付け、再利用できるようにします。その後、Apply from panel library をクリックしてプロットを完成させます。