- 단일 프로세스 추적: W&B를 사용하여 rank 0 프로세스( “leader” 또는 “coordinator”라고도 함)를 추적합니다. 이는 PyTorch Distributed Data Parallel (DDP) 클래스로 분산 트레이닝 실험을 로깅할 때 흔히 사용되는 솔루션입니다.
- 여러 프로세스 추적: 여러 프로세스의 경우 다음 중 하나를 선택할 수 있습니다.
- 프로세스당 하나의 run을 사용하여 각 프로세스를 개별적으로 추적합니다. 필요한 경우 W&B App UI에서 이들을 그룹화할 수 있습니다.
- 모든 프로세스를 단일 run으로 추적합니다.
단일 프로세스 추적
이 섹션에서는 rank 0 프로세스에서 사용 가능한 값과 메트릭을 추적하는 방법을 설명합니다. 단일 프로세스에서만 사용 가능한 메트릭을 추적하려는 경우 이 방식을 사용하세요. 일반적인 메트릭에는 GPU/CPU 사용률, 공유 검증 세트에서의 동작, 그레디언트 및 파라미터, 대표 데이터 샘플에 대한 loss 값 등이 포함됩니다. rank 0 프로세스 내에서wandb.init()으로 W&B run을 초기화하고 해당 run에 실험 내용을 로그(wandb.log)합니다.
다음 샘플 파이썬 스크립트 (log-ddp.py)는 PyTorch DDP를 사용하여 단일 머신의 두 GPU에서 메트릭을 추적하는 한 가지 방법을 보여줍니다. PyTorch DDP (torch.nn의 DistributedDataParallel)는 분산 트레이닝을 위한 인기 있는 라이브러리입니다. 기본 원칙은 모든 분산 트레이닝 설정에 적용되지만 구현은 다를 수 있습니다.
이 파이썬 스크립트는 다음을 수행합니다:
torch.distributed.launch를 사용하여 여러 프로세스를 시작합니다.--local_rank커맨드라인 인수를 사용하여 rank를 확인합니다.- rank가 0으로 설정된 경우,
train()함수에서 조건부로wandb로깅을 설정합니다.
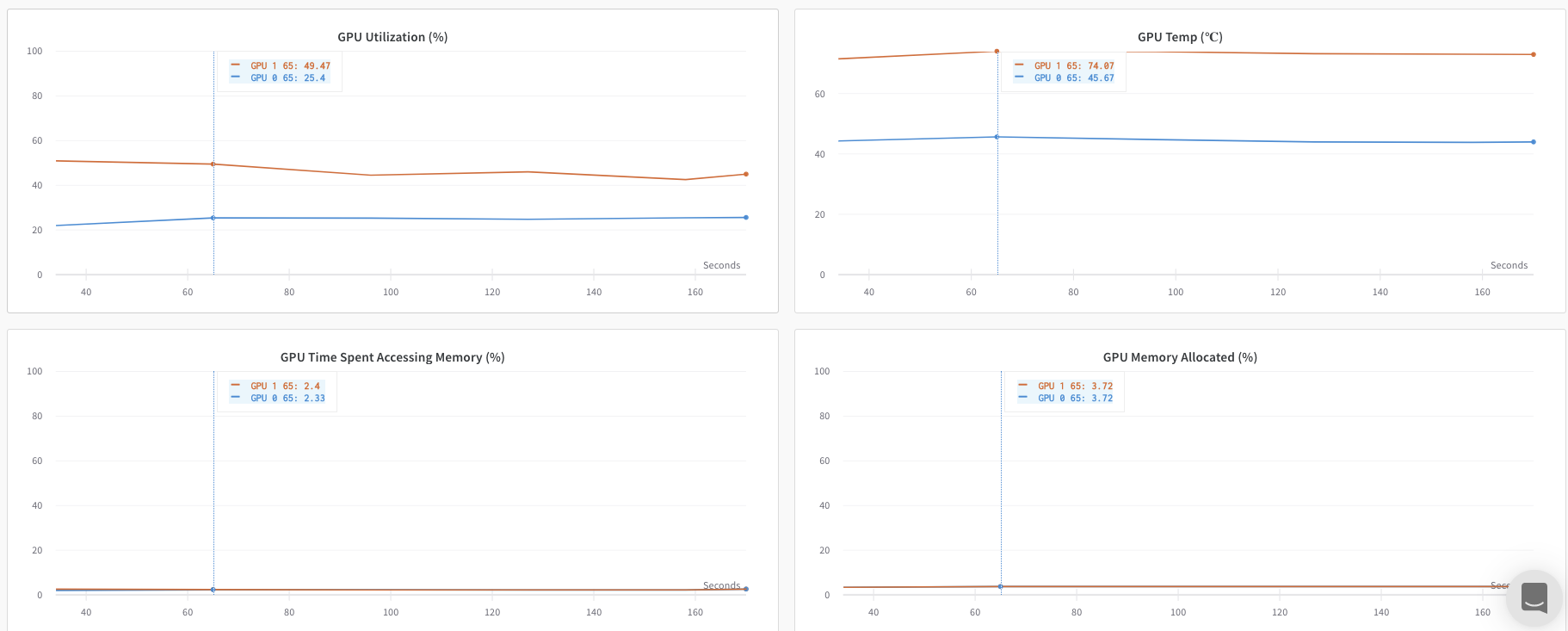
여러 프로세스 추적
다음 접근 방식 중 하나를 사용하여 W&B로 여러 프로세스를 추적할 수 있습니다.- 각 프로세스에 대한 run을 생성하여 각 프로세스를 개별적으로 추적.
- 모든 프로세스를 단일 run으로 추적.
각 프로세스별 추적
이 섹션에서는 각 프로세스에 대해 run을 생성하여 각 프로세스를 개별적으로 추적하는 방법을 설명합니다. 각 run 내에서 메트릭, Artifacts 등을 각각의 run에 로깅합니다. 트레이닝이 끝나면 모든 프로세스가 제대로 종료될 수 있도록wandb.Run.finish()를 호출하여 run이 완료되었음을 표시합니다.
여러 실험에 걸쳐 있는 run들을 관리하기 어려울 수 있습니다. 이를 완화하기 위해 W&B를 초기화할 때 group 파라미터에 값(wandb.init(group='group-name'))을 제공하여 해당 run이 어떤 실험에 속하는지 추적하세요. 실험에서 트레이닝 및 평가 W&B Runs를 추적하는 방법에 대한 자세한 내용은 Group Runs를 참조하세요.
개별 프로세스의 메트릭을 추적하려는 경우 이 방식을 사용하세요. 전형적인 예로는 각 노드의 데이터 및 예측값(데이터 분포 디버깅용)과 메인 노드 외의 개별 배치에 대한 메트릭이 있습니다. 모든 노드의 시스템 메트릭을 얻거나 메인 노드에서 사용 가능한 요약 통계를 얻는 데는 이 방식이 꼭 필요하지는 않습니다.
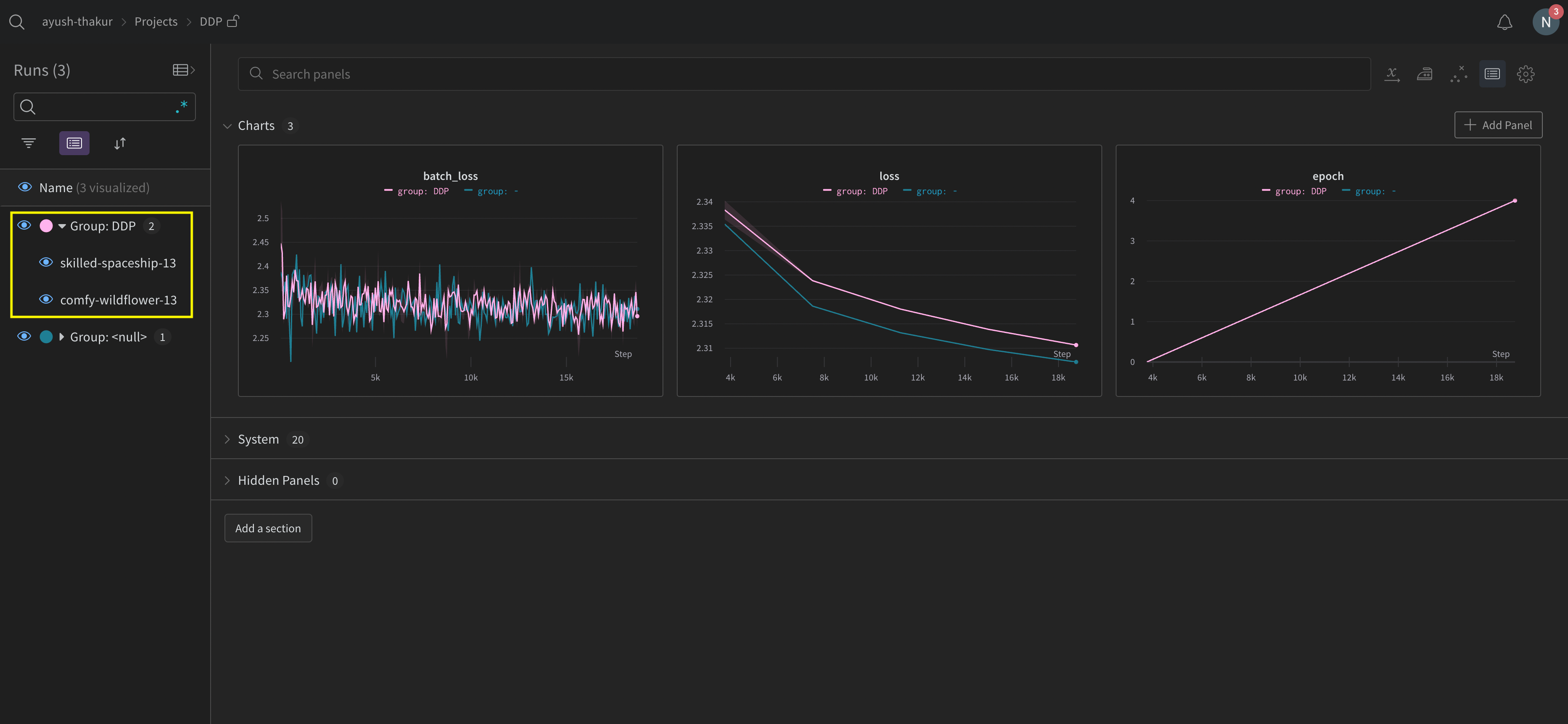
분산 run 정리하기
W&B를 초기화할 때job_type 파라미터(wandb.init(job_type='type-name'))를 설정하여 기능에 따라 노드를 분류하세요. 예를 들어, 하나의 메인 조정 노드와 여러 개의 보고용 워커 노드가 있을 수 있습니다. 메인 조정 노드에는 job_type을 main으로, 보고용 워커 노드에는 worker로 설정할 수 있습니다.
job_type을 설정한 후에는 Workspace에서 저장된 뷰(saved views)를 생성하여 run을 정리할 수 있습니다. 우측 상단의 … 액션 메뉴를 클릭하고 Save as new view를 클릭합니다.
예를 들어 다음과 같은 저장된 뷰를 생성할 수 있습니다:
-
기본 뷰 (Default view): 노이즈를 줄이기 위해 워커 노드를 필터링합니다.
- Filter를 클릭한 다음, Job Type을
worker가 아닌 것으로 설정합니다. - 메인 보고 노드만 표시됩니다.
- Filter를 클릭한 다음, Job Type을
-
디버그 뷰 (Debug view): 트러블슈팅을 위해 워커 노드에 집중합니다.
- Filter를 클릭한 다음, Job Type
==worker로 설정하고 State를INcrashed로 설정합니다. - 충돌이 발생했거나 오류 상태인 워커 노드만 표시됩니다.
- Filter를 클릭한 다음, Job Type
-
모든 노드 뷰 (All nodes view): 모든 것을 함께 봅니다.
- 필터 없음.
- 종합적인 모니터링에 유용합니다.
모든 프로세스를 단일 run으로 추적
요구 사항여러 프로세스를 단일 run으로 추적하려면 다음이 필요합니다:
- W&B Python SDK 버전
v0.19.9이상. - W&B Server v0.68 이상.
wandb.init()으로 W&B run을 초기화합니다. settings 파라미터에 다음과 같은 내용이 포함된 wandb.Settings 오브젝트를 전달합니다(wandb.init(settings=wandb.Settings())):
- 공유 모드를 활성화하기 위해
mode파라미터를"shared"로 설정합니다. x_label에 고유한 레이블을 지정합니다.x_label에 지정한 값은 W&B App UI의 로그 및 시스템 메트릭에서 어떤 노드에서 데이터가 오는지 식별하는 데 사용됩니다. 지정하지 않으면 W&B가 호스트 이름과 랜덤 해시를 사용하여 레이블을 생성합니다.- 이 노드가 프라이머리 노드임을 나타내기 위해
x_primary파라미터를True로 설정합니다. - 선택적으로
x_stats_gpu_device_ids에 GPU 인덱스 리스트([0,1,2])를 제공하여 W&B가 메트릭을 추적할 GPU를 지정합니다. 리스트를 제공하지 않으면 W&B는 머신의 모든 GPU에 대한 메트릭을 추적합니다.
x_primary=True는 프라이머리 노드를 워커 노드와 구분합니다. 프라이머리 노드는 설정 파일, 텔레메트리 등 노드 간에 공유되는 파일을 업로드하는 유일한 노드입니다. 워커 노드는 이러한 파일을 업로드하지 않습니다.wandb.init()으로 W&B run을 초기화하고 다음을 제공합니다:
settings파라미터에 다음이 포함된wandb.Settings오브젝트를 전달합니다:- 공유 모드를 활성화하기 위해
mode파라미터를"shared"로 설정합니다. x_label에 고유한 레이블을 지정합니다.x_label에 지정한 값은 W&B App UI의 로그 및 시스템 메트릭에서 데이터의 출처를 식별하는 데 사용됩니다.- 이 노드가 워커 노드임을 나타내기 위해
x_primary파라미터를False로 설정합니다.
- 공유 모드를 활성화하기 위해
id파라미터에 프라이머리 노드에서 사용한 run ID를 전달합니다.- 선택적으로
x_update_finish_state를False로 설정합니다. 이는 프라이머리 노드가 아닌 노드가 run의 상태를 조기에finished로 업데이트하는 것을 방지하여, run 상태가 일관되게 유지되고 프라이머리 노드에 의해 관리되도록 보장합니다.
- 모든 노드에 대해 동일한 Entity와 Project를 사용하세요. 이는 올바른 run ID를 찾는 데 도움이 됩니다.
- 각 워커 노드에 프라이머리 노드의 run ID를 설정하기 위한 환경 변수를 정의하는 것을 고려해 보세요.
GKE의 멀티 노드 및 멀티 GPU Kubernetes 클러스터에서 모델을 트레이닝하는 방법에 대한 엔드투엔드 예제는 Distributed Training with Shared Mode 리포트를 참조하세요.
- 해당 run이 포함된 프로젝트로 이동합니다.
- 왼쪽 사이드바에서 Runs 탭을 클릭합니다.
- 확인하려는 run을 클릭합니다.
- 왼쪽 사이드바에서 Logs 탭을 클릭합니다.
x_label에 제공한 레이블을 기준으로 콘솔 로그를 필터링할 수 있습니다. 예를 들어, 다음 이미지는 x_label에 rank0, rank1, rank2, rank3, rank4, rank5, rank6 값이 제공되었을 때 콘솔 로그를 필터링할 수 있는 옵션들을 보여줍니다.
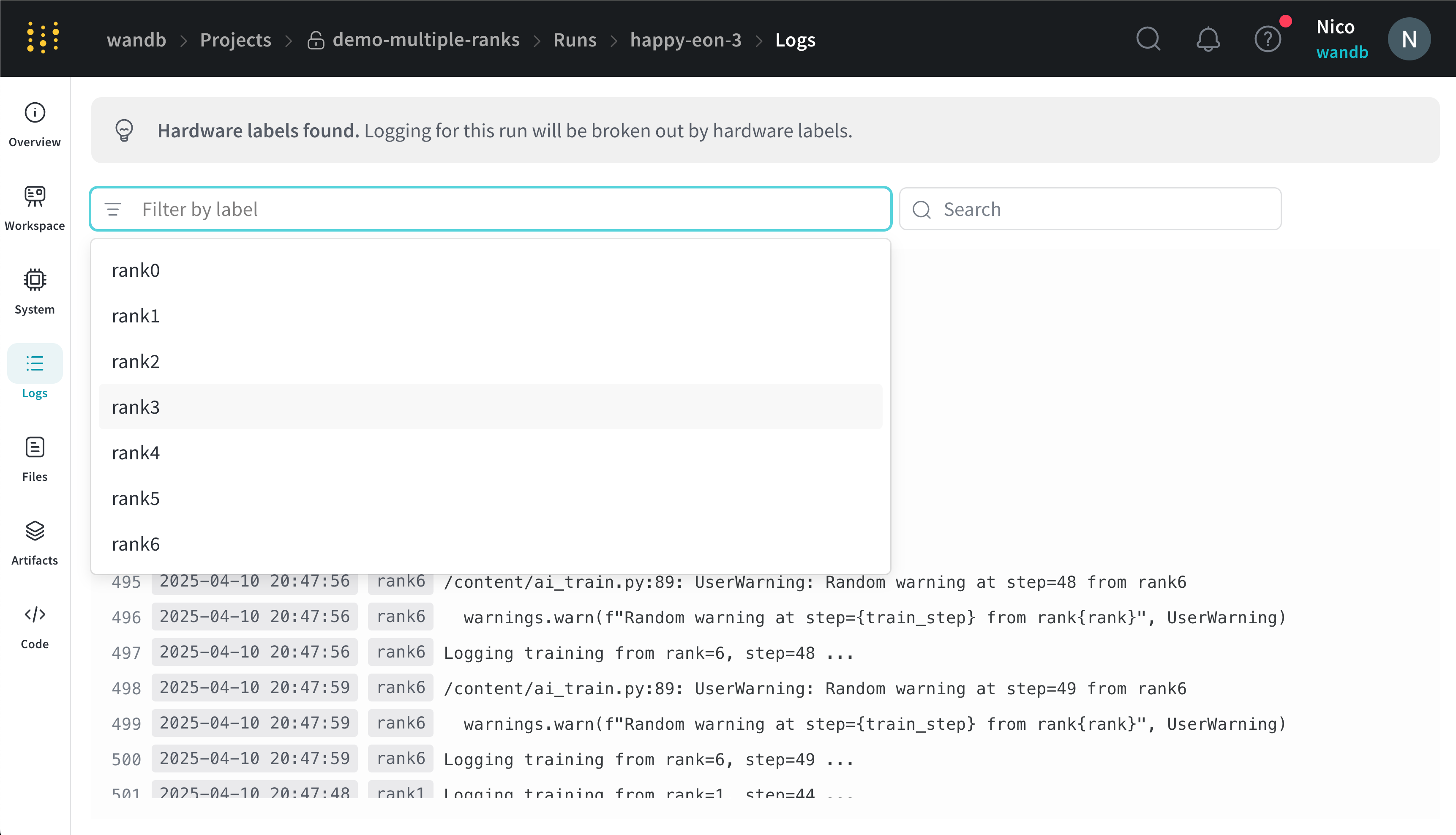
x_label 파라미터에서 지정한 고유한 레이블(rank_0, rank_1, rank_2)을 가집니다.
예제 유스 케이스
다음 코드 조각들은 고급 분산 시나리오에서의 일반적인 상황들을 보여줍니다.프로세스 생성 (Spawn process)
생성된 프로세스(spawned process)에서 run을 시작하는 경우 메인 함수에서wandb.setup() 메소드를 사용하세요.
run 공유하기
프로세스 간에 run을 공유하려면 run 오브젝트를 인수로 전달하세요.문제 해결
W&B와 분산 트레이닝을 사용할 때 발생할 수 있는 두 가지 일반적인 문제가 있습니다.- 트레이닝 시작 시 멈춤(Hanging) -
wandb멀티프로세싱이 분산 트레이닝의 멀티프로세싱과 충돌하면wandb프로세스가 멈출 수 있습니다. - 트레이닝 종료 시 멈춤(Hanging) -
wandb프로세스가 언제 종료되어야 하는지 알지 못하면 트레이닝 작업이 멈출 수 있습니다. 파이썬 스크립트 끝에서wandb.Run.finish()API를 호출하여 W&B에 run이 완료되었음을 알리세요.wandb.Run.finish()API는 데이터 업로드를 완료하고 W&B를 종료시킵니다. W&B는 분산 작업의 안정성을 향상시키기 위해wandb service코맨드 사용을 권장합니다. 위의 두 가지 트레이닝 문제는 주로 wandb service를 사용할 수 없는 구버전 W&B SDK에서 발견됩니다.
W&B Service 활성화
W&B SDK 버전에 따라 W&B Service가 이미 기본으로 활성화되어 있을 수 있습니다.W&B SDK 0.13.0 이상
W&B SDK0.13.0 이상의 버전에서는 W&B Service가 기본으로 활성화되어 있습니다.
W&B SDK 0.12.5 이상
W&B SDK 0.12.5 이상 버전에서 W&B Service를 활성화하려면 파이썬 스크립트를 수정하세요. 메인 함수 내에서wandb.require 메소드를 사용하고 "service" 문자열을 전달합니다.
WANDB_START_METHOD 환경 변수를 "thread"로 설정하여 대신 멀티스레딩을 사용하세요.