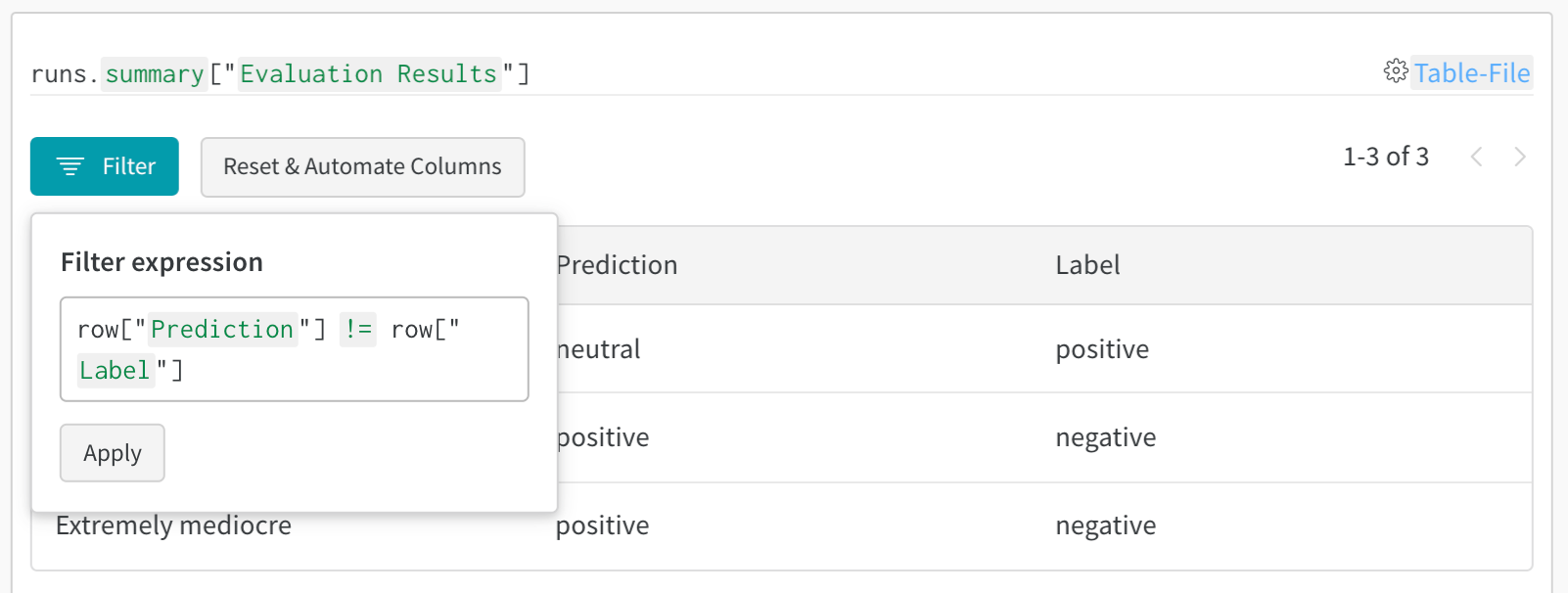
1. Table を ログ に記録する
W&B で Table の ログ を記録します。新しい Table を構築するか、 Pandas Dataframe を渡すことができます。- Table を構築する
- Pandas Dataframe
新しい Table を構築して ログ に記録するには、以下を使用します:
wandb.init(): 結果を追跡するための run を作成します。wandb.Table(): 新しい Table オブジェクト を作成します。columns: カラム名を設定します。data: 各行の内容を設定します。
wandb.Run.log(): Table を ログ に記録して W&B に保存します。
2. プロジェクトの Workspace で Tables を可視化する
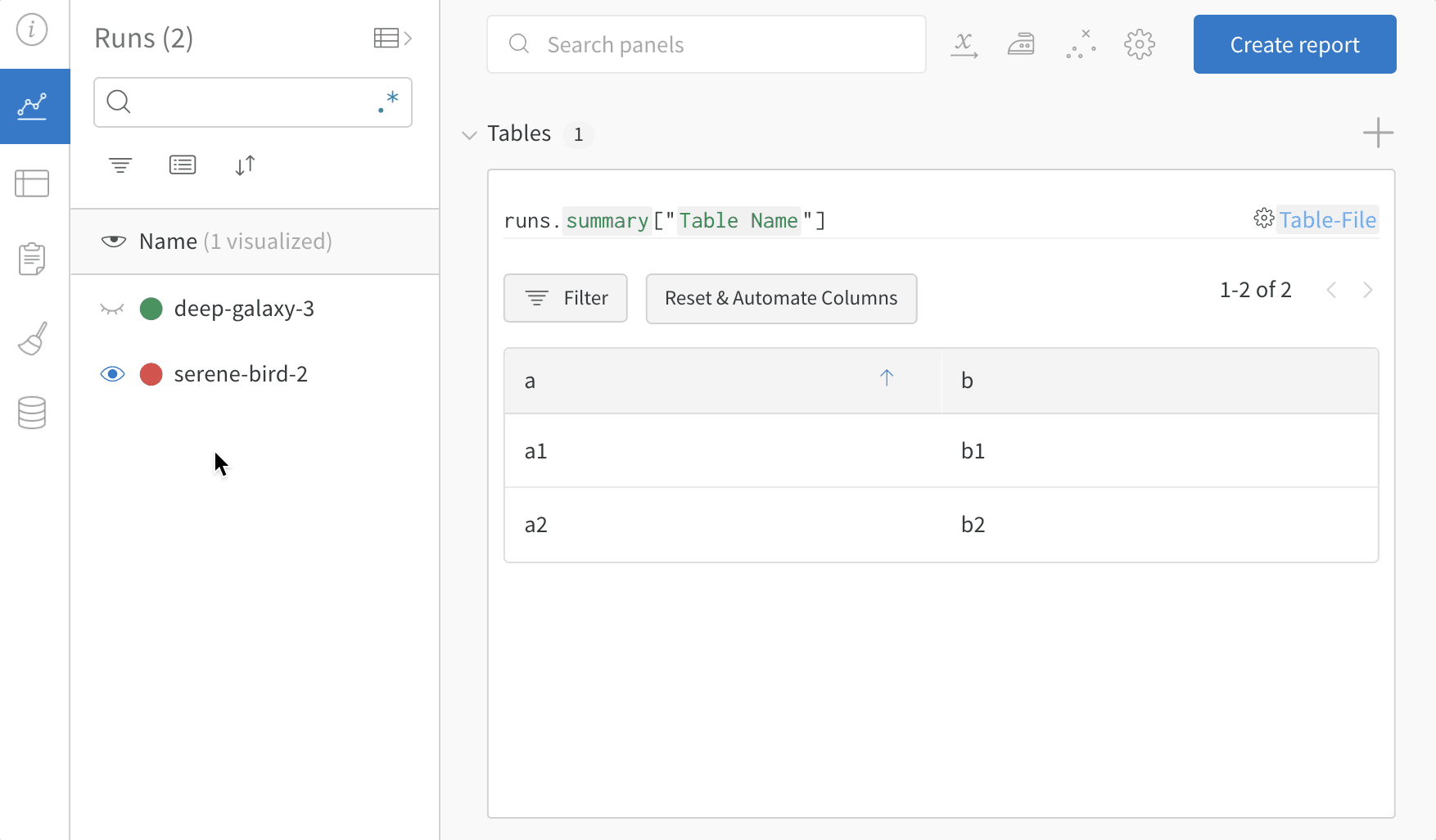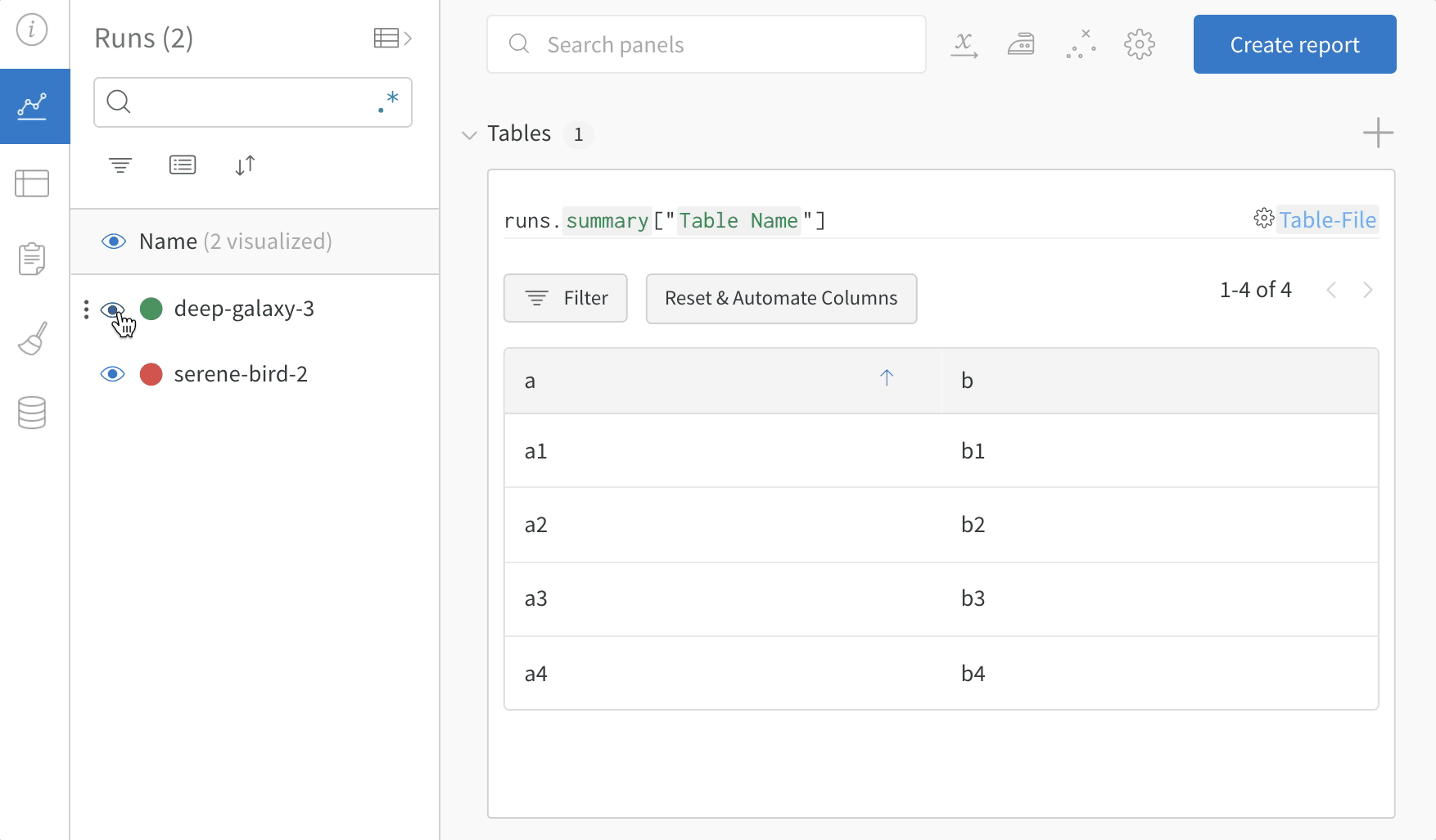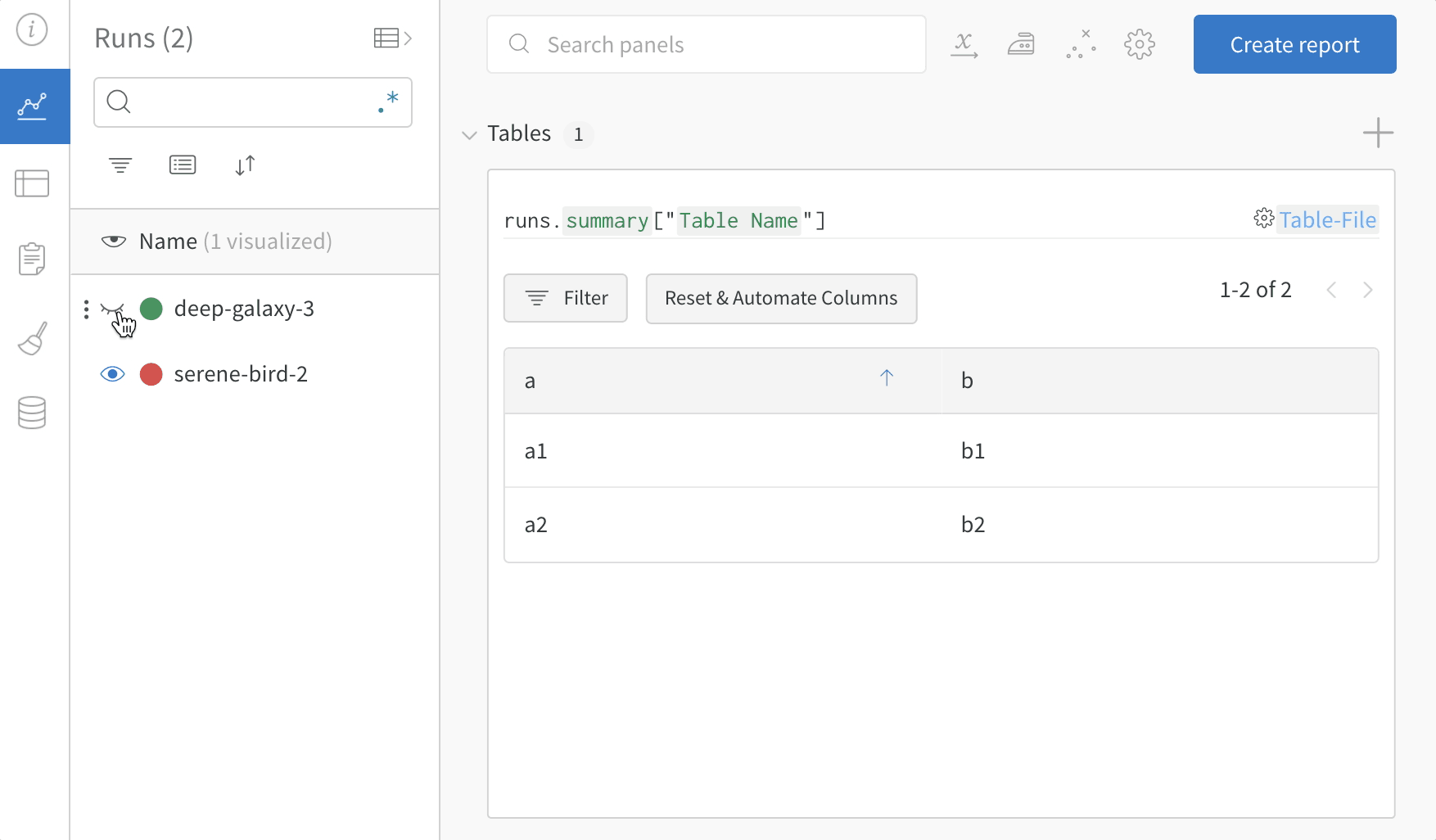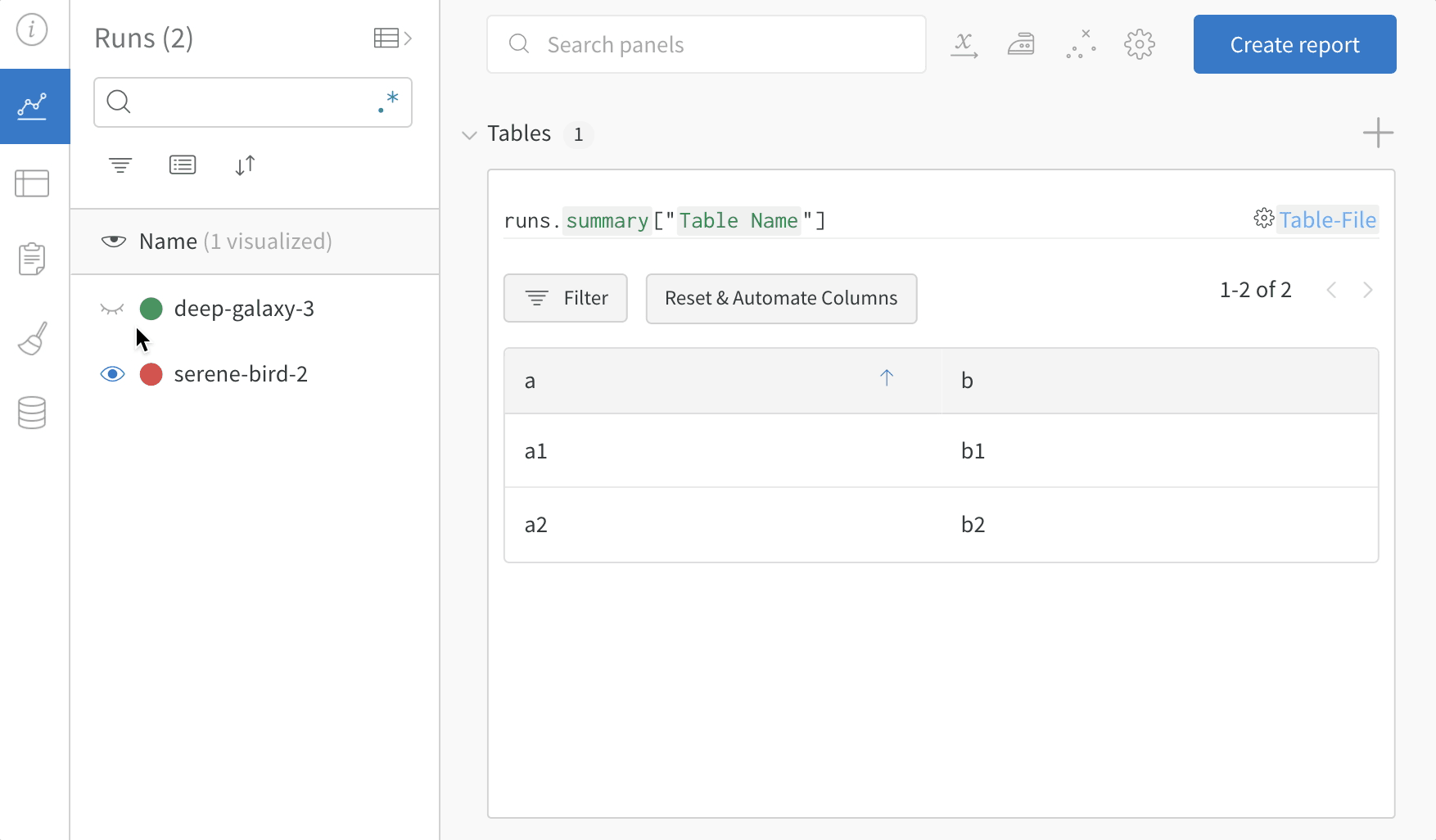
Workspace で生成された Table を確認します。- W&B App で自らの プロジェクト に移動します。
- プロジェクト の Workspace で run の名前を選択します。一意の Table キー ごとに新しい パネル が追加されます。
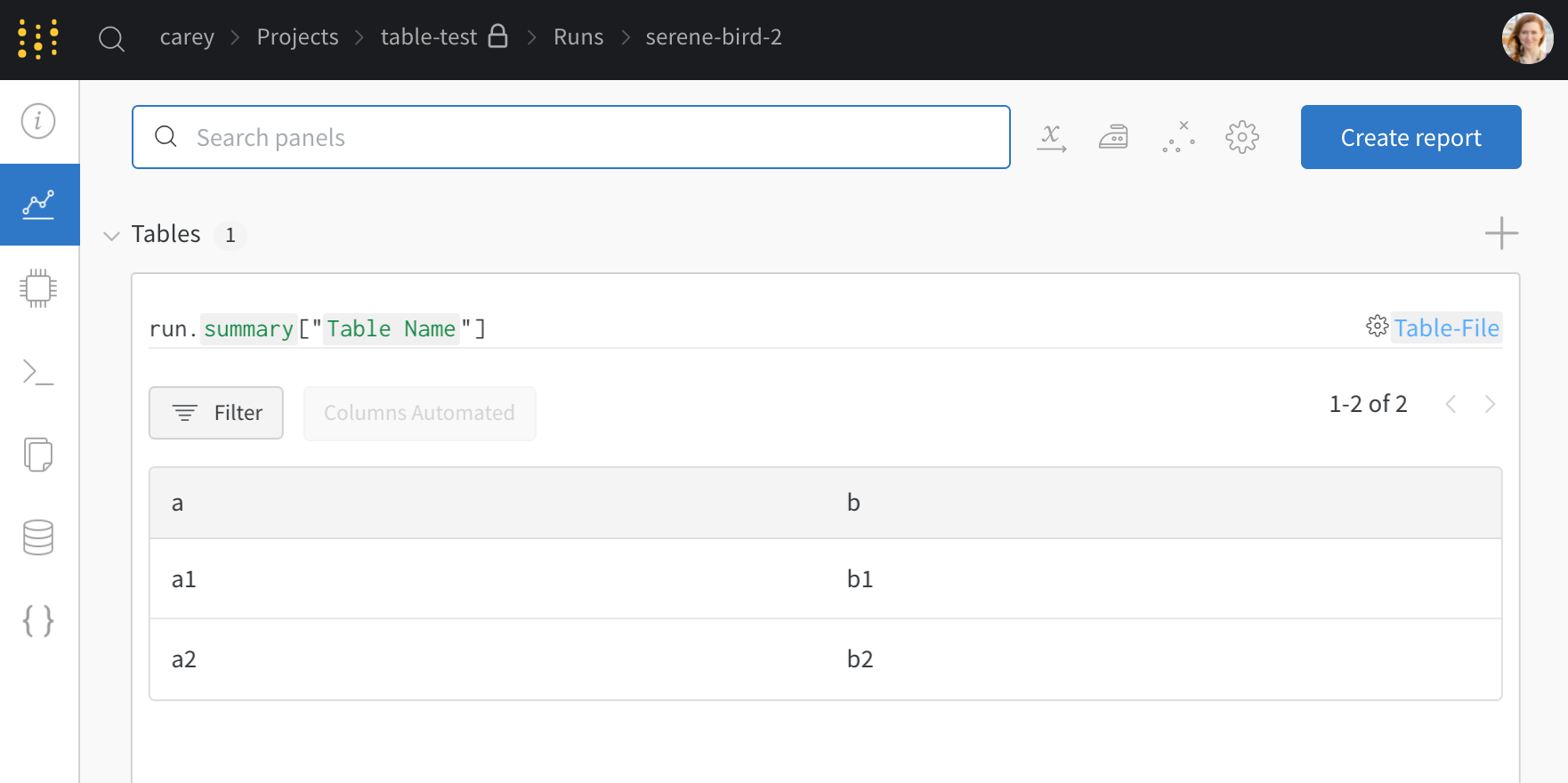
my_table は "Table Name" という キー の下に ログ 記録されています。
3. モデル の バージョン 間で比較する
複数の W&B Runs からサンプル Table を ログ 記録し、 プロジェクト の Workspace で 結果 を比較します。この サンプル Workspace では、複数の異なる バージョン からの行を同じ Table 内で結合する方法を示しています。