- 単一プロセスのトラッキング: ランク 0 のプロセス(「リーダー」または「コーディネーター」とも呼ばれます)を W&B でトラッキングします。これは、PyTorch Distributed Data Parallel (DDP) クラスを使用して分散トレーニング実験をログ記録するための一般的なソリューションです。
- 複数プロセスのトラッキング: 複数のプロセスの場合、以下のいずれかを選択できます:
- プロセスごとに1つの run を使用して、各プロセスを個別にトラッキングする。オプションで、W&B App UI でこれらをグループ化できます。
- すべてのプロセスを単一の run にトラッキングする。
単一プロセスのトラッキング
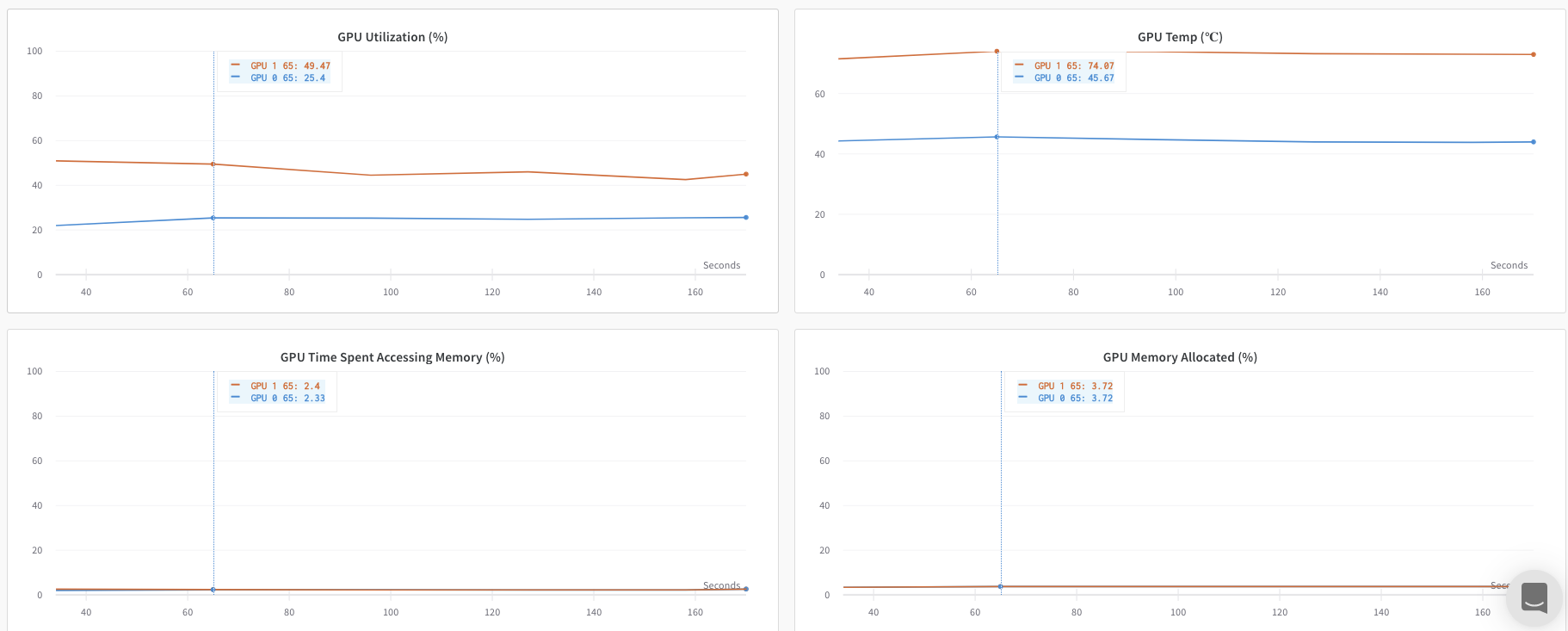
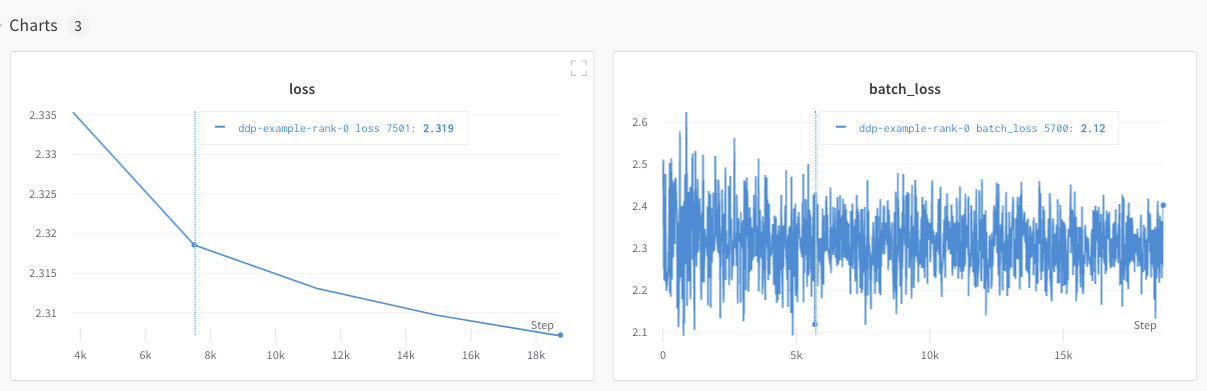
このセクションでは、ランク 0 プロセスで利用可能な値とメトリクスをトラッキングする方法について説明します。単一のプロセスからのみ取得可能なメトリクスをトラッキングする場合に、このアプローチを使用します。一般的なメトリクスには、GPU/CPU 使用率、共有検証セットでの振る舞い、勾配とパラメータ、代表的なデータ例での損失(loss)値などがあります。 ランク 0 プロセス内で、wandb.init() を使用して W&B run を初期化し、その run に実験をログ記録(wandb.log)します。
以下の サンプル Python スクリプト (log-ddp.py) は、PyTorch DDP を使用して単一マシンの 2 つの GPU でメトリクスをトラッキングする 1 つの方法を示しています。PyTorch DDP (torch.nn の DistributedDataParallel) は、分散トレーニングで人気のあるライブラリです。基本的な原理はあらゆる分散トレーニングのセットアップに適用されますが、実装は異なる場合があります。
この Python スクリプトは以下のことを行います:
torch.distributed.launchを使用して複数のプロセスを開始します。--local_rankコマンドライン引数でランクを確認します。- ランクが 0 に設定されている場合、
train()関数内で条件付きでwandbロギングをセットアップします。
複数プロセスのトラッキング
W&B で複数のプロセスをトラッキングするには、次のいずれかのアプローチを使用します:- プロセスごとに run を作成して 各プロセスを個別にトラッキングする。
- すべてのプロセスを単一の run にトラッキングする。
各プロセスを個別にトラッキングする
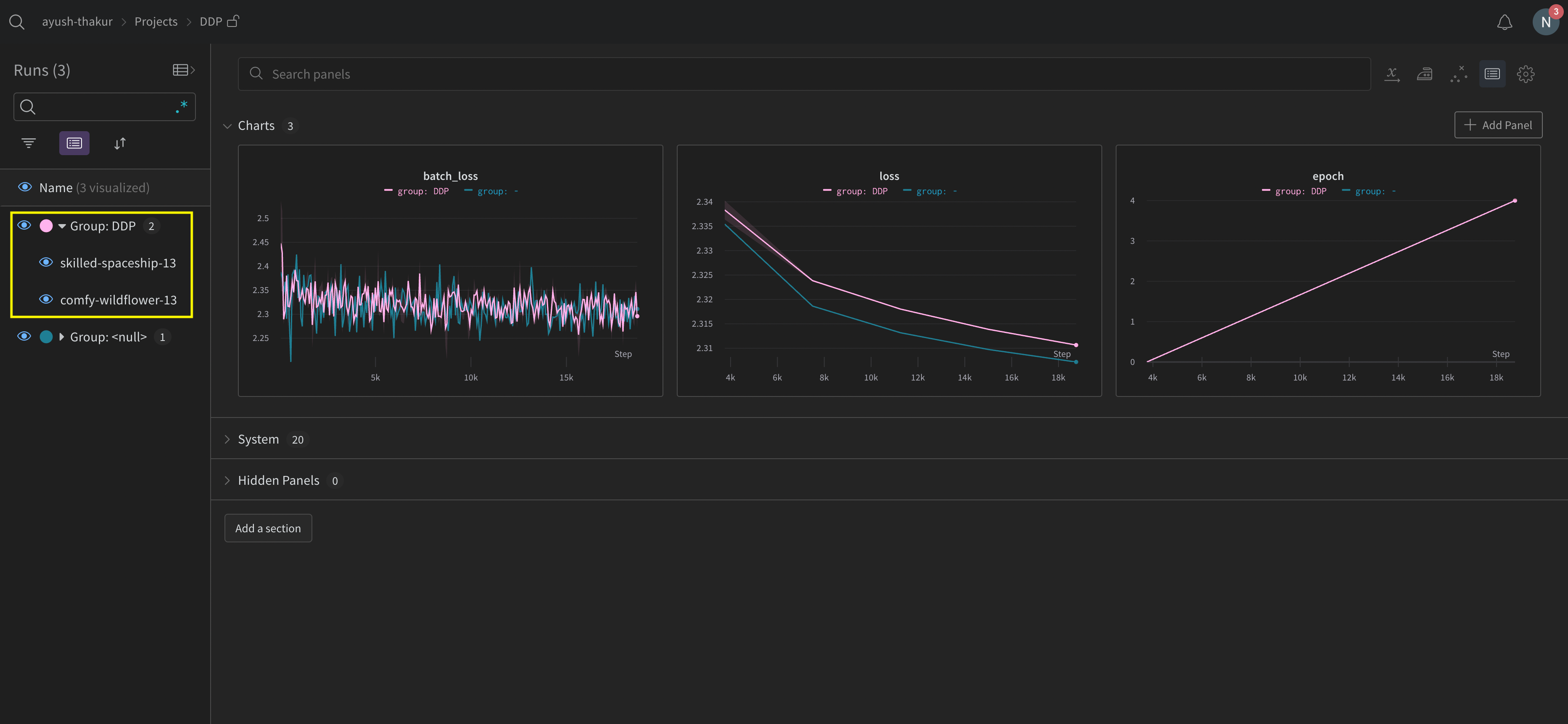
このセクションでは、プロセスごとに run を作成して、各プロセスを個別にトラッキングする方法について説明します。各 run 内で、メトリクスやアーティファクトなどをそれぞれの run にログ記録します。トレーニングの最後にwandb.Run.finish() を呼び出して run が完了したことをマークし、すべてのプロセスが適切に終了するようにします。
複数の実験にわたって run を追跡するのが難しい場合があります。これを軽減するために、W&B を初期化する際に group パラメータに値を指定し(wandb.init(group='group-name'))、どの run が特定の実験に属しているかを把握できるようにします。実験におけるトレーニングと評価の W&B Runs を追跡する方法の詳細については、Group Runs を参照してください。
個々のプロセスからメトリクスをトラッキングしたい場合に、このアプローチを使用してください。典型的な例としては、各ノードでのデータや予測(データ分散のデバッグ用)、メインノード以外の個々のバッチのメトリクスなどがあります。すべてのノードからシステムメトリクスを取得したり、メインノードで利用可能なサマリー統計を取得したりするだけであれば、このアプローチは必要ありません。
分散 run の整理
W&B を初期化する際にjob_type パラメータを設定し(wandb.init(job_type='type-name'))、機能に基づいてノードをカテゴリ分けします。例えば、1 つのメインコーディネートノードと複数のレポート用ワーカーノードがある場合、メインコーディネートノードには job_type を main に、レポート用ワーカーノードには worker に設定できます。
job_type を設定したら、Workspace で 保存済みビュー を作成して run を整理できます。右上の … アクションメニューをクリックし、Save as new view をクリックします。
例えば、以下のような保存済みビューを作成できます:
-
デフォルトビュー: ノイズを減らすためにワーカーノードをフィルタリングして除外する
- Filter をクリックし、Job Type を
worker以外に設定します。 - レポート用ノードのみを表示します。
- Filter をクリックし、Job Type を
-
デバッグビュー: トラブルシューティングのためにワーカーノードに焦点を当てる
- Filter をクリックし、Job Type
==workerかつ State をINcrashedに設定します。 - クラッシュした、またはエラー状態にあるワーカーノードのみを表示します。
- Filter をクリックし、Job Type
-
全ノードビュー: すべてをまとめて表示する
- フィルタなし
- 包括的なモニタリングに役立ちます。
すべてのプロセスを単一の run にトラッキングする
要件複数のプロセスを単一の run にトラッキングするには、以下が必要です:
- W&B Python SDK バージョン
v0.19.9以降。 - W&B Server v0.68 以降。
wandb.init() を使用して W&B run を初期化します。settings パラメータに wandb.Settings オブジェクト(wandb.init(settings=wandb.Settings())を渡し、以下を設定します:
- 共有モードを有効にするために、
modeパラメータを"shared"に設定します。 x_labelに一意のラベルを指定します。x_labelに指定した値を使用して、W&B App UI のログやシステムメトリクスでデータがどのノードから来ているかを識別します。指定しない場合、W&B はホスト名とランダムなハッシュを使用してラベルを自動作成します。x_primaryパラメータをTrueに設定して、これがプライマリノードであることを示します。- オプションで、W&B がメトリクスをトラッキングする GPU を指定するために、GPU インデックスのリスト([0,1,2])を
x_stats_gpu_device_idsに提供します。リストを提供しない場合、W&B はマシン上のすべての GPU のメトリクスをトラッキングします。
x_primary=True は、プライマリノードをワーカーノードと区別します。プライマリノードは、設定ファイルやテレメトリなど、ノード間で共有されるファイルをアップロードする唯一のノードです。ワーカーノードはこれらのファイルをアップロードしません。wandb.init() を使用して W&B run を初期化し、以下を提供します:
settingsパラメータにwandb.Settingsオブジェクト(wandb.init(settings=wandb.Settings())を渡し、以下を設定:- 共有モードを有効にするために、
modeパラメータを"shared"に設定。 x_labelに一意のラベルを指定。x_labelに指定した値を使用して、W&B App UI のログやシステムメトリクスでデータがどのノードから来ているかを識別します。指定しない場合、W&B はホスト名とランダムなハッシュを使用してラベルを自動作成します。x_primaryパラメータをFalseに設定して、これがワーカーノードであることを示す。
- 共有モードを有効にするために、
- プライマリノードで使用されている run ID を
idパラメータに渡す。 - オプションで
x_update_finish_stateをFalseに設定します。これにより、プライマリ以外のノードが run の状態 を途中でfinishedに更新するのを防ぎ、run の状態が一貫してプライマリノードによって管理されるようになります。
- すべてのノードで同じ Entity と Project を使用してください。これにより、正しい run ID が見つかるようになります。
- 各ワーカーノードで、プライマリノードの run ID を設定するための環境変数を定義することを検討してください。
GKE 上のマルチノード・マルチ GPU Kubernetes クラスターでモデルをトレーニングする方法のエンドツーエンドの例については、Distributed Training with Shared Mode レポートを参照してください。
- run が含まれているプロジェクトに移動します。
- 左側のサイドバーにある Runs タブをクリックします。
- 表示したい run をクリックします。
- 左側のサイドバーにある Logs タブをクリックします。
x_label に指定したラベルに基づいてコンソールログをフィルタリングできます。例えば、次の画像は、x_label に rank0、rank1、rank2、rank3、rank4、rank5、rank6 が指定されている場合に、コンソールログをフィルタリングするために利用可能なオプションを示しています。
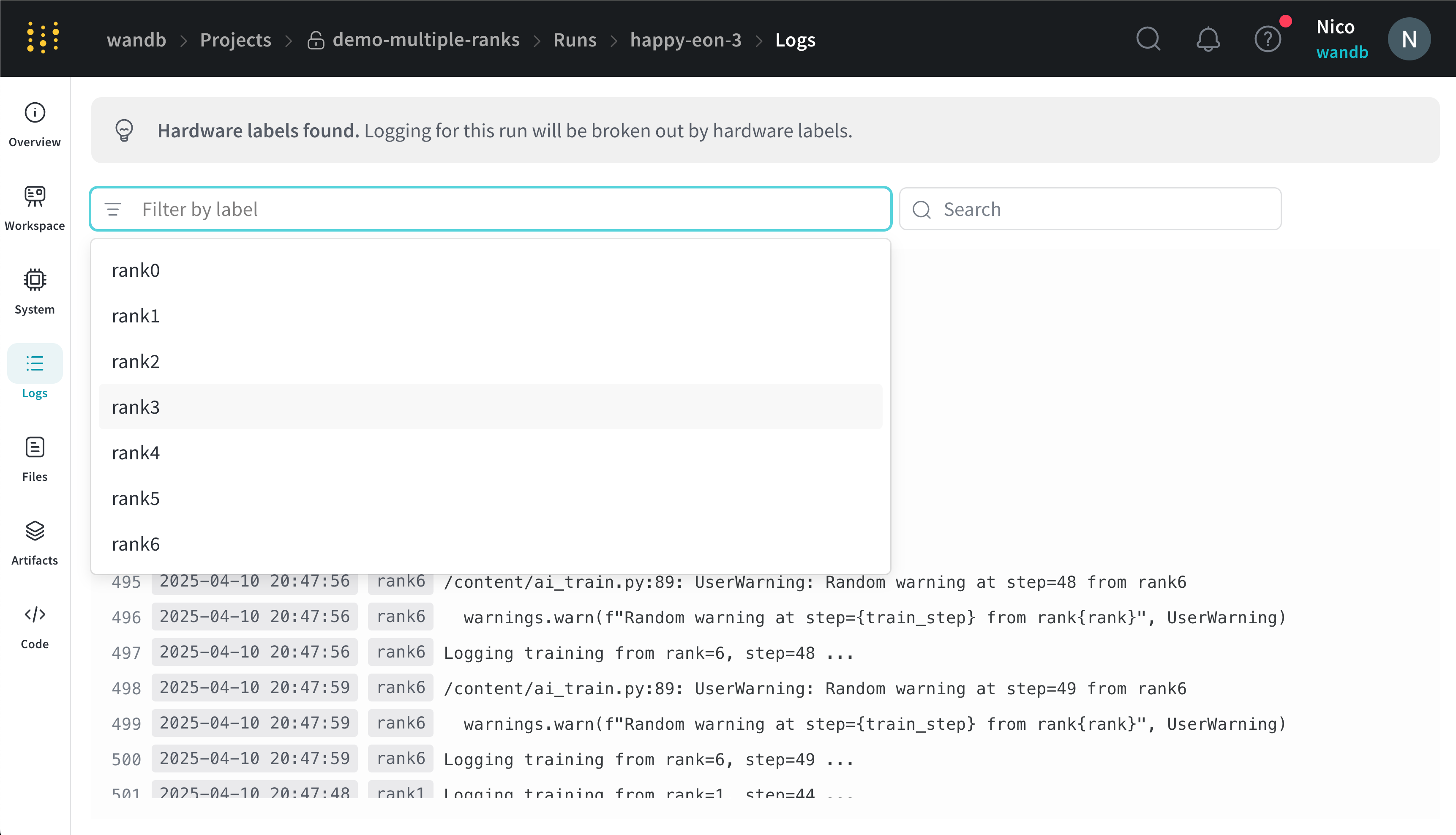
x_label パラメータで指定した一意のラベル(rank_0、rank_1、rank_2)を持っています。
ユースケースの例
以下のコードスニペットは、高度な分散ユースケースの一般的なシナリオを示しています。プロセスの spawn
spawn されたプロセスで run を開始する場合は、メイン関数内でwandb.setup() メソッドを使用します:
run の共有
プロセス間で run を共有するには、run オブジェクトを引数として渡します:トラブルシューティング
W&B と分散トレーニングを使用する際に遭遇する可能性のある 2 つの一般的な問題があります:- トレーニング開始時にハングする -
wandbのマルチプロセッシングが分散トレーニングのマルチプロセッシングと干渉すると、wandbプロセスがハングすることがあります。 - トレーニング終了時にハングする -
wandbプロセスがいつ終了すべきかを認識していない場合、トレーニングジョブがハングすることがあります。Python スクリプトの最後でwandb.Run.finish()API を呼び出し、W&B に run が終了したことを伝えてください。wandb.Run.finish()API はデータのアップロードを完了させ、W&B を終了させます。 W&B は、分散ジョブの信頼性を向上させるためにwandb serviceコマンドの使用を推奨しています。上記のトレーニングの問題は両方とも、wandb service が利用できない古いバージョンの W&B SDK でよく見られます。
W&B Service の有効化
W&B SDK のバージョンによっては、すでにデフォルトで W&B Service が有効になっている場合があります。W&B SDK 0.13.0 以上
W&B SDK バージョン0.13.0 以上では、W&B Service がデフォルトで有効になっています。
W&B SDK 0.12.5 以上
W&B SDK バージョン 0.12.5 以上で W&B Service を有効にするには、Python スクリプトを変更します。メイン関数内でwandb.require メソッドを使用し、文字列 "service" を渡します:
WANDB_START_METHOD 環境変数を "thread" に設定して、代わりにマルチスレッディングを使用するようにしてください。