Full fidelity
full fidelity 모드를 사용하면, W&B는 데이터 포인트의 수에 따라 x축을 동적 버킷으로 나눕니다. 그런 다음 각 버킷 내에서 최소값, 최대값 및 평균값을 계산하여 라인 플롯에 대한 포인트 집계를 렌더링합니다. 포인트 집계에 full fidelity 모드를 사용하면 세 가지 주요 장점이 있습니다:- 극단값 및 스파이크 보존: 데이터의 극단값과 스파이크(spikes)를 유지합니다.
- 최소 및 최대 포인트 렌더링 방식 설정: W&B 앱을 사용하여 극단값(최소/최대)을 음영 영역으로 표시할지 여부를 대화식으로 결정할 수 있습니다.
- 데이터 충실도 유지하며 데이터 탐색: 특정 데이터 포인트를 확대할 때 W&B가 x축 버킷 크기를 다시 계산합니다. 이를 통해 정확도를 잃지 않고 데이터를 탐색할 수 있습니다. 캐싱을 사용하여 이전에 계산된 집계 데이터를 저장하므로 로딩 시간을 줄여주며, 특히 대규모 데이터셋을 탐색할 때 유용합니다.
최소 및 최대 포인트 렌더링 방식 설정
라인 플롯 주변에 음영 영역을 표시하여 최소값과 최대값을 시각화하거나 숨길 수 있습니다. 다음 이미지는 파란색 라인 플롯을 보여줍니다. 연한 파란색 음영 영역은 각 버킷의 최소값과 최대값을 나타냅니다.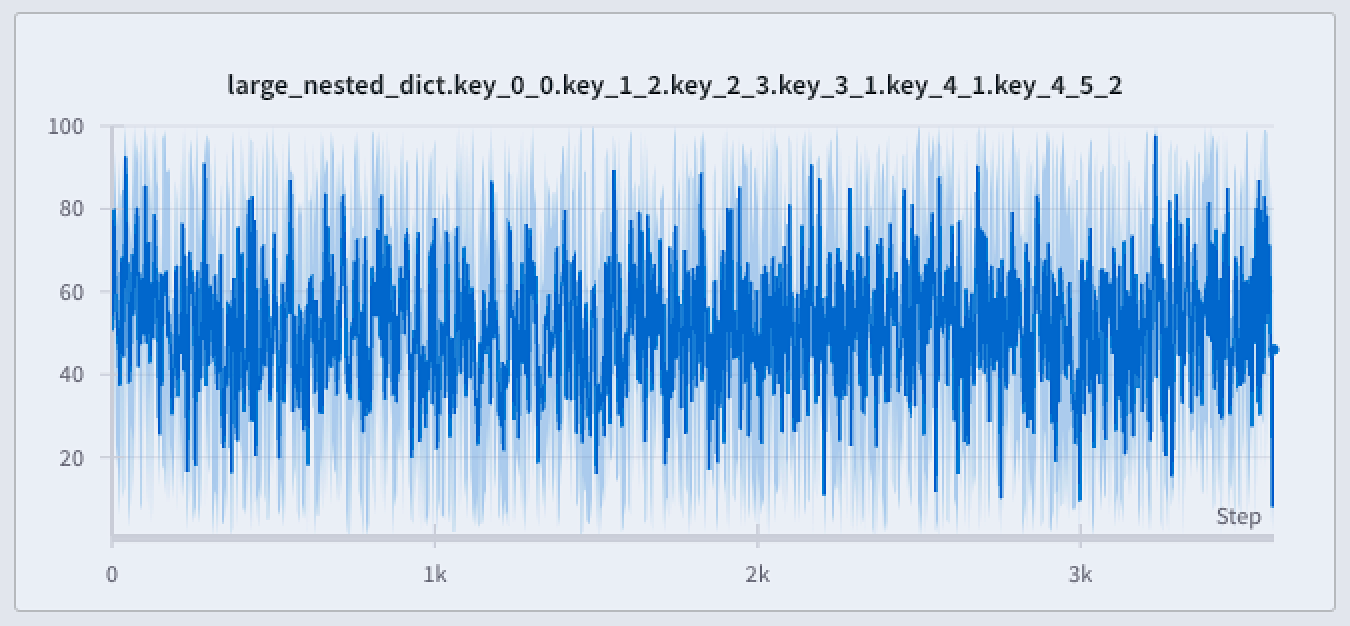
- Never: 최소/최대값이 음영 영역으로 표시되지 않습니다. x축 버킷에 대한 집계된 라인만 표시합니다.
- On hover: 차트 위에 마우스를 올릴 때만 최소/최대값에 대한 음영 영역이 동적으로 나타납니다. 이 옵션은 뷰를 깔끔하게 유지하면서 범위를 대화식으로 검사할 수 있게 해줍니다.
- Always: 차트의 모든 버킷에 대해 최소/최대 음영 영역이 지속적으로 표시되어, 항상 전체 값 범위를 시각화할 수 있도록 도와줍니다. 차트에 시각화된 Runs가 많을 경우 시각적 노이즈가 발생할 수 있습니다.
- Workspace의 모든 차트
- Workspace의 개별 차트
- W&B Projects로 이동합니다.
- 왼쪽 탭에서 Workspace 아이콘을 선택합니다.
- Add panels 버튼 왼쪽, 화면 오른쪽 상단 모서리에 있는 기어 아이콘을 선택합니다.
- 나타나는 UI 슬라이더에서 Line plots를 선택합니다.
- Point aggregation 섹션 내의 Show min/max values as a shaded area 드롭다운 메뉴에서 On hover 또는 Always를 선택합니다.
데이터 충실도 유지하며 데이터 탐색
극단값이나 스파이크와 같은 중요한 포인트를 놓치지 않고 데이터셋의 특정 영역을 분석하세요. 라인 플롯을 확대하면 W&B는 각 버킷 내의 최소, 최대 및 평균값을 계산하는 데 사용되는 버킷 크기를 조정합니다.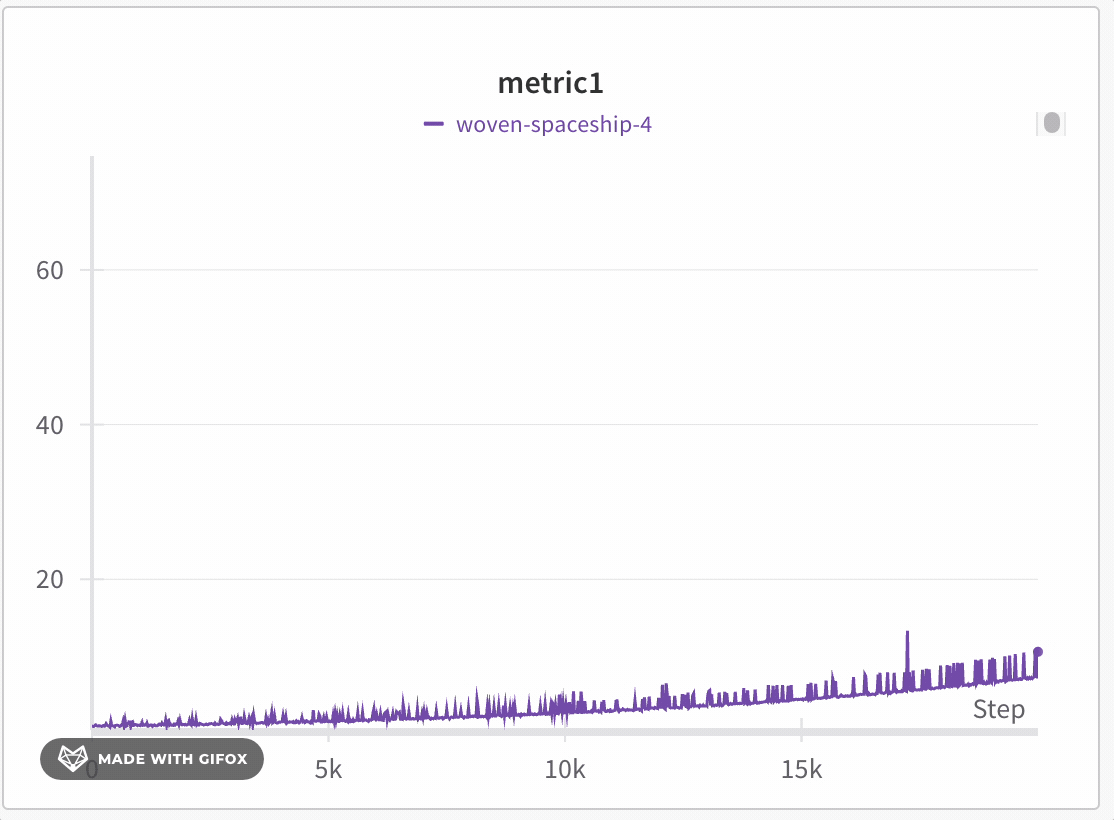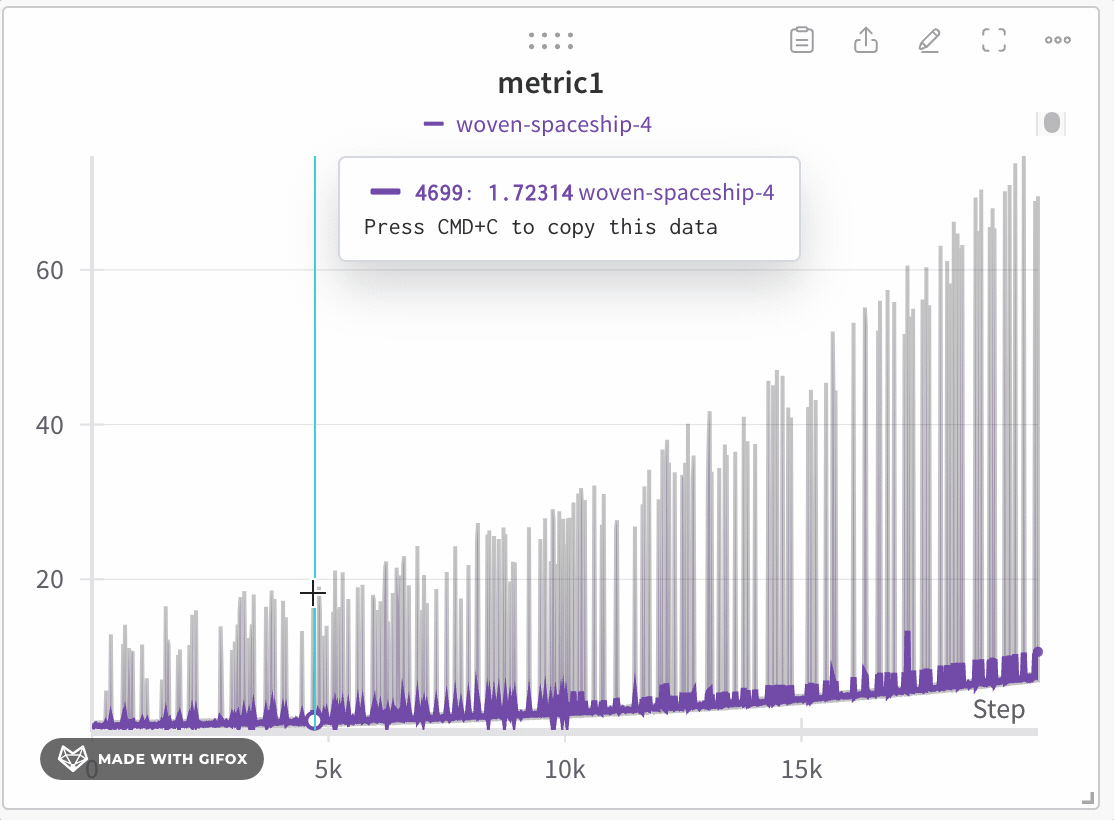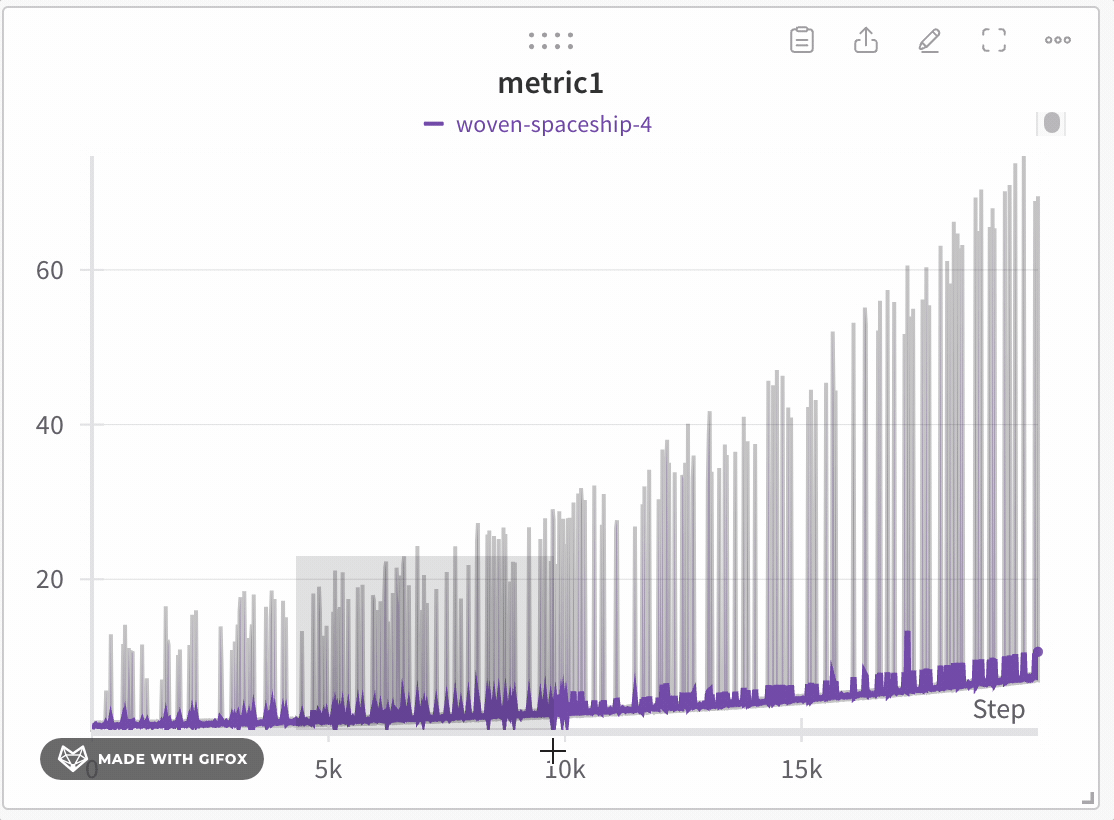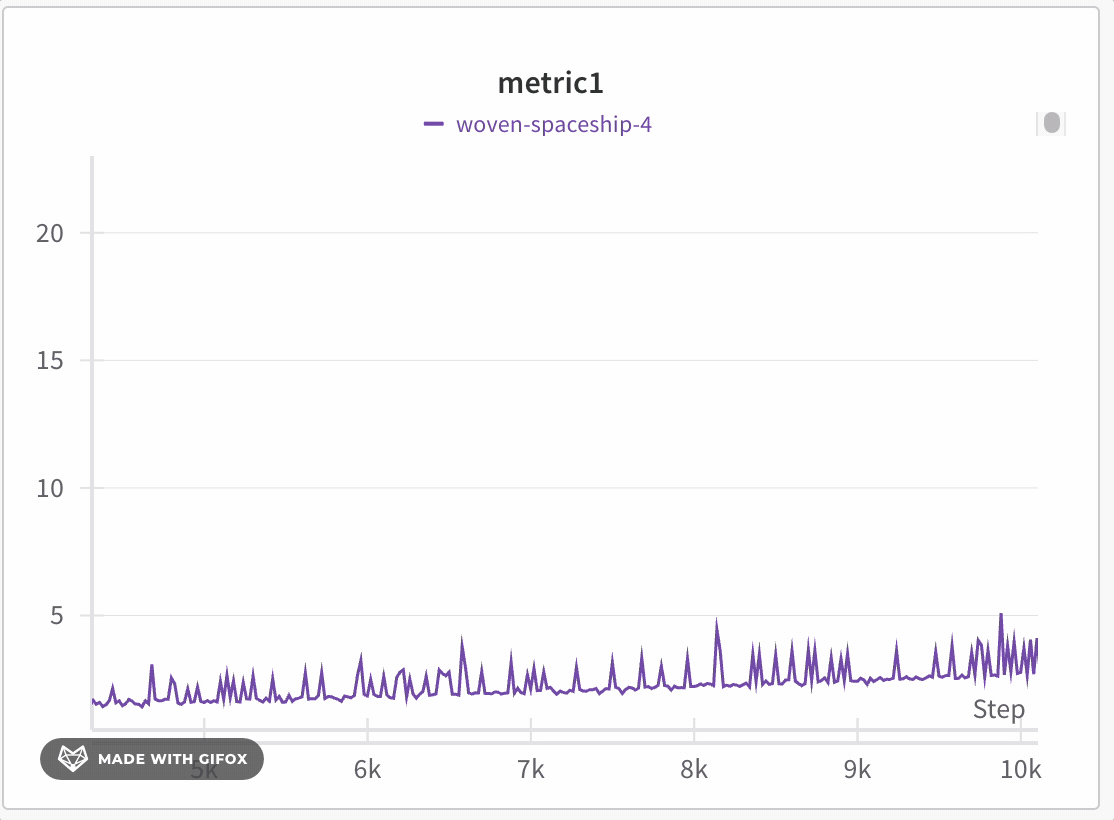
- Minimum: 해당 버킷의 가장 낮은 값.
- Maximum: 해당 버킷의 가장 높은 값.
- Average: 해당 버킷에 있는 모든 포인트의 평균값.
- W&B Projects로 이동합니다.
- 왼쪽 탭에서 Workspace 아이콘을 선택합니다.
- 선택적으로 Workspace에 라인 플롯 패널을 추가하거나 기존 라인 플롯 패널로 이동합니다.
- 클릭 후 드래그하여 확대할 특정 영역을 선택합니다.
라인 플롯 그룹화 및 표현식라인 플롯 그룹화(Line Plot Grouping)를 사용할 때 W&B는 선택된 모드에 따라 다음을 적용합니다:
- Non-windowed sampling (grouping): x축의 Runs 전반에 걸쳐 포인트를 정렬합니다. 여러 포인트가 동일한 x값을 공유하면 평균을 취하고, 그렇지 않으면 이산 포인트로 나타납니다.
- Windowed sampling (grouping and expressions): x축을 250개의 버킷 또는 가장 긴 라인의 포인트 수(둘 중 더 작은 값)로 나눕니다. W&B는 각 버킷 내 포인트의 평균을 취합니다.
- Full fidelity (grouping and expressions): non-windowed sampling과 유사하지만, 성능과 디테일의 균형을 맞추기 위해 run당 최대 500개의 포인트를 가져옵니다.
Random sampling
Random sampling은 라인 플롯을 렌더링하기 위해 무작위로 샘플링된 1500개의 포인트를 사용합니다. Random sampling은 데이터 포인트 수가 매우 많을 때 성능상의 이유로 유용합니다.Random sampling 활성화
기본적으로 W&B는 full fidelity 모드를 사용합니다. Random sampling을 활성화하려면 다음 단계를 따르세요:- Workspace의 모든 차트
- Workspace의 개별 차트
- W&B Projects로 이동합니다.
- 왼쪽 탭에서 Workspace 아이콘을 선택합니다.
- Add panels 버튼 왼쪽, 화면 오른쪽 상단 모서리에 있는 기어 아이콘을 선택합니다.
- 나타나는 UI 슬라이더에서 Line plots를 선택합니다.
- Point aggregation 섹션에서 Random sampling을 선택합니다.